Difference between revisions of "Laurmagee: Week 9"
(→Using SQL Queries to Validate the PostgreSQL Database Results from the TallyEngine) |
(→OriginalRowCounts Comparison) |
||
| Line 50: | Line 50: | ||
Copy the OriginalRowCounts table and paste it here: | Copy the OriginalRowCounts table and paste it here: | ||
| + | Table Rows | ||
| + | Info 1 | ||
| + | |||
| + | Systems 30 | ||
| + | |||
| + | Relations 18 | ||
| + | |||
| + | Other 0 | ||
| + | |||
| + | GeneOntologyTree 97982 | ||
| + | |||
| + | GeneOntology 5556 | ||
| + | |||
| + | UniProt-GOCount 3240 | ||
| + | |||
| + | GeneOntologyCount 3239 | ||
| + | |||
| + | UniProt-GeneOntology 20464 | ||
| + | |||
| + | UniProt 3784 | ||
| + | |||
| + | Pfam 2102 | ||
| + | |||
| + | RefSeq 3403 | ||
| + | |||
| + | PDB 223 | ||
| + | |||
| + | InterPro 4349 | ||
| + | |||
| + | OrderedLocusNames 3832 | ||
| + | |||
| + | EMBL 228 | ||
| + | |||
| + | UniProt-EMBL 5452 | ||
| + | |||
| + | UniProt-OrderedLocusNames 3832 | ||
| + | |||
| + | UniProt-PDB 319 | ||
| + | |||
| + | UniProt-InterPro 10393 | ||
| + | |||
| + | UniProt-RefSeq 3635 | ||
| + | |||
| + | UniProt-Pfam 4648 | ||
| + | |||
| + | RefSeq-Pfam 4145 | ||
| + | |||
| + | RefSeq-InterPro 9241 | ||
| + | |||
| + | RefSeq-PDB 234 | ||
| + | |||
| + | RefSeq-OrderedLocusNames 3520 | ||
| + | |||
| + | RefSeq-EMBL 3669 | ||
| + | |||
| + | OrderedLocusNames-Pfam 4367 | ||
| + | |||
| + | OrderedLocusNames-InterPro 9723 | ||
| + | |||
| + | OrderedLocusNames-PDB 235 | ||
| + | |||
| + | OrderedLocusNames-EMBL 4111 | ||
| + | |||
| + | RefSeq-GeneOntology 18931 | ||
| + | |||
| + | OrderedLocusNames-GeneOntology 20613 | ||
Note: | Note: | ||
Revision as of 05:27, 25 October 2013
Export Information
Version of GenMAPP Builder: 2.0b70
Computer on which export was run: last row of computer in the lab; second computer from the right when facing the front of the classroom.
Postgres Database name: Vibrio cholerae serotype O1_10_22_LM_KM
UniProt XML filename:File:Vibrio cholerae serotype O1 10 22 LM KM.xml
- UniProt XML version (The version information can be found at the UniProt News Page): UniProt release 2013_10
- Time taken to import: 8.49 minutes
GO OBO-XML filename:File:Go daily-termdb.obo-10 22-LM-KM.xml.gz
- Direct Download from Wiki due to connectivity problems.
- GO OBO-XML version (The version information can be found in the file properties after the file downloaded from the GO Download page has been unzipped):
- format-version: 1.2
- data-version: 2013-10-22
- Time taken to import:20.02 minutes
- Time taken to process: 14.78 minutes
GOA filename: File:46.V cholerae ATCC 39315 10 22 LM KM.txt
- GOA version (News on this page records past releases; current information can be found in the Last modified field on the FTP site): last updated Oct 14, 2013 8:56 AM
- Time taken to import: 0.16 minutes
Name of .gdb file: File:Vc-Std 20131022 LM KM-gmb2b70.gdb
- Time taken to export .gdb: about 4 hours and 20 minutes
Note: Export started around 11 am; ended at 3:19:06 pm.
TallyEngine

Using XMLPipeDB match to Validate the XML Results from the TallyEngine
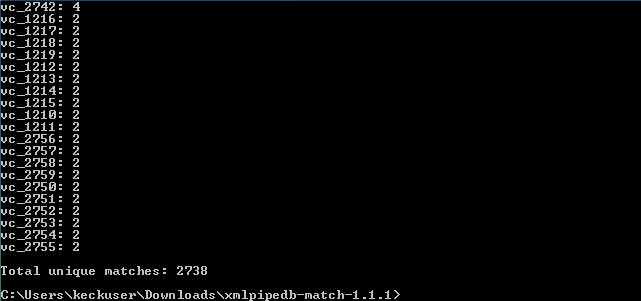
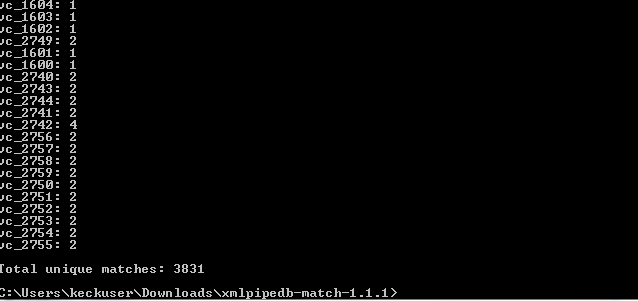
- Are your results the same as you got for the TallyEngine? Why or why not?
- When running the Command Line, the top picture represents the command java -jar xmlpipedb-match-1.1.1.jar "VC_[0-9][0-9][0-9][0-9]" < uniprot-46.V_cholerae_ATCC_39315.xml. The reason this results in a lower number of matches (2738) is because we are not accounting for the inclusion of possible letter A's in identification. To do this we add (A|) into the pattern portion of our command (ie. java -jar xmlpipedb-match-1.1.1.jar "VC_(A|) [0-9][0-9][0-9][0-9]" < uniprot-46.V_cholerae_ATCC_39315.xml) and we receive the feedback of the second picture. This shows 3831 matches, which is what we expect after seeing our TallyEngine results.
.PNG)
.PNG)
Using SQL Queries to Validate the PostgreSQL Database Results from the TallyEngine
- Follow the instructions on this page to query the PostgreSQL Database.
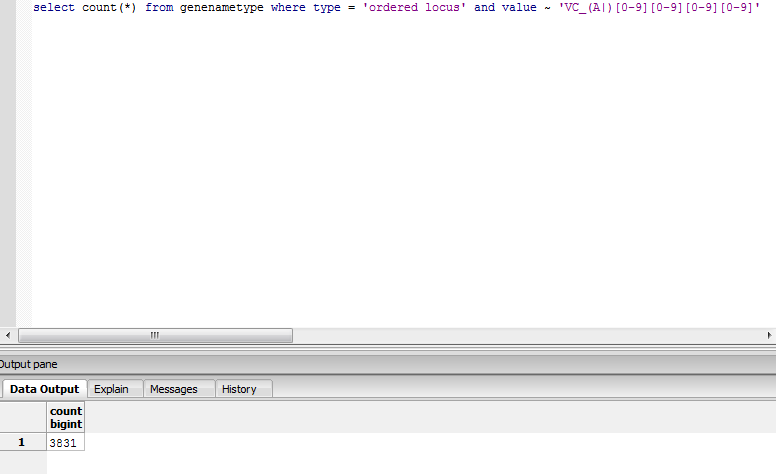
- From the above picture, we see that SQL gives us the same match total of 3831.

OriginalRowCounts Comparison
Within the .gdb file, look at the OriginalRowCounts table to see if the database has the expected tables with the expected number of records. Compare the tables and records with a benchmark .gdb file.
Benchmark .gdb file: (for the Week 9 Assignment, use the "Vc-Std_External_20101022.gdb" as your benchmark, downloadable from here.
Copy the OriginalRowCounts table and paste it here: Table Rows
Info 1
Systems 30
Relations 18
Other 0
GeneOntologyTree 97982
GeneOntology 5556
UniProt-GOCount 3240
GeneOntologyCount 3239
UniProt-GeneOntology 20464
UniProt 3784
Pfam 2102
RefSeq 3403
PDB 223
InterPro 4349
OrderedLocusNames 3832
EMBL 228
UniProt-EMBL 5452
UniProt-OrderedLocusNames 3832
UniProt-PDB 319
UniProt-InterPro 10393
UniProt-RefSeq 3635
UniProt-Pfam 4648
RefSeq-Pfam 4145
RefSeq-InterPro 9241
RefSeq-PDB 234
RefSeq-OrderedLocusNames 3520
RefSeq-EMBL 3669
OrderedLocusNames-Pfam 4367
OrderedLocusNames-InterPro 9723
OrderedLocusNames-PDB 235
OrderedLocusNames-EMBL 4111
RefSeq-GeneOntology 18931
OrderedLocusNames-GeneOntology 20613 Note:

Visual Inspection
Perform visual inspection of individual tables to see if there are any problems.
- Look at the Systems table. Is there a date in the Date field for all gene ID systems present in the database?
- Open the UniProt, RefSeq, and OrderedLocusNames tables. Scroll down through the table. Do all of the IDs look like they take the correct form for that type of ID?
Note:
.gdb Use in GenMAPP
Note:
Putting a gene on the MAPP using the GeneFinder window
- Try a sample ID from each of the gene ID systems. Open the Backpage and see if all of the cross-referenced IDs that are supposed to be there are there.
Note:
Creating an Expression Dataset in the Expression Dataset Manager
- How many of the IDs were imported out of the total IDs in the microarray dataset? How many exceptions were there? Look in the EX.txt file and look at the error codes for the records that were not imported into the Expression Dataset. Do these represent IDs that were present in the UniProt XML, but were somehow not imported? or were they not present in the UniProt XML?
Note:
Coloring a MAPP with expression data
Note:
Running MAPPFinder
Note:
Compare Gene Database to Outside Resource
The OrderedLocusNames IDs in the exported Gene Database are derived from the UniProt XML. It is a good idea to check your list of OrderedLocusNames IDs to see how complete it is using the original source of the data (the sequencing organization, the MOD, etc.) Because UniProt is a protein database, it does not reference any non-protein genome features such as genes that code for functional RNAs, centromeres, telomeres, etc.
Note: