Difference between revisions of "Jwoodlee Week 9"
(→Using XMLPipeDB match to Validate the XML Results from the TallyEngine: fixed a faulty command) |
(→OriginalRowCounts Comparison: added benchmark file) |
||
| Line 104: | Line 104: | ||
Within the .gdb file, look at the OriginalRowCounts table to see if the database has the expected tables with the expected number of records. Compare the tables and records with a benchmark .gdb file. | Within the .gdb file, look at the OriginalRowCounts table to see if the database has the expected tables with the expected number of records. Compare the tables and records with a benchmark .gdb file. | ||
| − | Benchmark .gdb file: | + | Benchmark .gdb file: [[File:Vc-Std_External_20101022.gdb|Vc-Std_External_20101022]] |
Copy the OriginalRowCounts table from the benchmark and new gdb and paste them here: | Copy the OriginalRowCounts table from the benchmark and new gdb and paste them here: | ||
Revision as of 01:12, 3 November 2015
13-Oct-2015 07:31 5.0M date and time of v cholerae download from GenMAPP builder page
Contents
- 1 Export Information
- 2 TallyEngine
- 3 Using XMLPipeDB match to Validate the XML Results from the TallyEngine
- 4 Using SQL Queries to Validate the PostgreSQL Database Results from the TallyEngine
- 5 OriginalRowCounts Comparison
- 6 Visual Inspection
- 7 .gdb Use in GenMAPP
- 8 Compare Gene Database to Outside Resource
Export Information
Version of GenMAPP Builder: 2.0 Beta
Computer on which export was run: Seaver 120 computer lab, facing the front of the room the computer on the far left in the front row, Windows 7
Postgres Database name: Vcholerae_20151027_gmb3build5
In a windows environment I went to UniProt Complete Proteomes and clicked on download, and then download all, and then selected XML from the drop down menu in the compressed format. To get the next file I navigated to here, to download this text file I clicked on the link, and then hit Ctrl-S to save it. To get the GO OBO-XML file go here, and under Legacy Downloads click on "obo-xml.gz". Now extract the Uniprot XML and the GO OBO-XML.gz files using an unzipping utility such as 7.zip.
Creating the .gdb
Then in order to create the .gdb file, I navigated to Download gmbuilder-3.0.0-build-5.zip. The download should start automatically. I extracted the contents of the .zip file. I launched pgAdmin III and in PostgreSQL 9.4 I right clicked on Databases and selected New Database, I then put in my database name and clicked OK. I clicked on my new database name and clicked the SQL icon in the toolbar. In the SQL query box I clicked the yellow open button and navigated to the folder which had the unzipped GenMAPP builder file. I opened the SQL folder and opened the file gmbuilder.sql. When the code appeared, I clicked the green arrow which executes my query. I then verified that there were 167 tables.
In my folder with my GenMAPP builder file I launched gmbuilder.bat, I selected on the menu File > Configure Database. Under the Database Connections tab the Database Driver defaults to PostgreSQL. I entered information in the following fields: Host or address: localhost Port number: 5432 Database name: <enter the name of the PostgreSQL database you created above> my name is: Vc-Std_20151027_JAW Username: <enter the username of the PostgreSQL database you created above>; in S120, this username is "postgres", so for me I entered postgres Password: <enter the password of the PostgreSQL database you created above>; in S120, ask the instructors for the password, the password is Welcome1 I clicked the OK button.
I went to File > Import UniProt XML... and navigated to the Uniprot XML file that I previously extracted. I went to File > Import GO OBO-XML... and navigated to the GO OBO-XML file that I extracted previously, and clicked the Open button.
Then clicked OK to the message asking to process the GO data. I then went to File > Import GOA File... And I navigated to the GOA file that I downloaded previously and clicked the Import button.
I then selected Select File > Export to GenMAPP Gene Database... Typed my name in the owner field, and selected my species, which in this case is Vibrio cholerae. I clicked next and then hit "save GenMAPP Database file as...", I then made the name I wanted to save it as. I kept all the boxes checked. I then hit the Next button to begin the process. It ened 1 hour and 15 minutes later. More detail about this process is below.
UniProt XML filename (give filename and upload and link to compressed file):File:Uniprot-organism-243277 Jwoodlee.xml.gz
- UniProt XML version (The version information can be found at the UniProt News Page): 10/27/2015 3:10 PM
- UniProt XML download link: here
- Time taken to import: 2.81 minutes
- Note:
GO OBO-XML filename (give filename and upload and link to compressed file): File:Go daily-termdb.obo-xml Jwoodlee.gz
- GO OBO-XML version (The version information can be found in the file properties after the file downloaded from the GO Download page has been unzipped): 10/27/2015 3:16 PM
- GO OBO-XML download link:here
- Time taken to import: 6.97 minutes
- Time taken to process: 4.48 minutes
- Note:
GOA filename (give filename and upload and link to compressed file): File:46.V cholerae ATCC 39315 Jwoodlee.goa.txt
- GOA version (News on this page records past releases; current information can be found in the Last modified field on the FTP site): 13-Oct-2015 07:31 5.0M
- GOA download link:here
- Time taken to import: 0.06 minutes
- Note:
Name of .gdb file (give filename and upload and link to compressed file): File:Vc-Std 20151027 JAW.gdb
- Time taken to export: 1 Hour 15 Minutes
- Start time: 3:54 PM
- End time: 5:09 PM
Note:
TallyEngine
- I Ran the TallyEngine in GenMAPP Builder and recorded the number of records for UniProt and GO in the XML data and in the Postgres databases.
- I chose the menu item Tallies > Run XML and Database Tallies for UniProt and GO... this was the result.
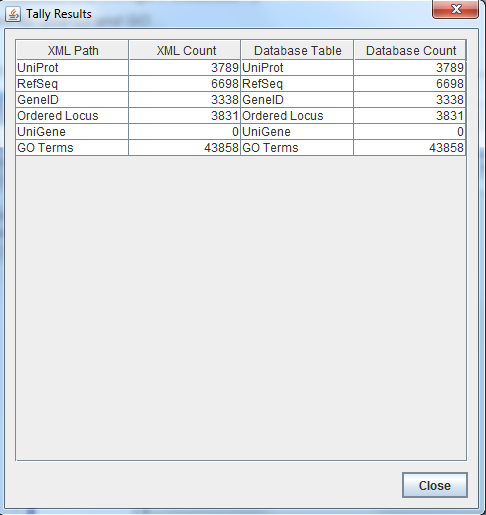

Using XMLPipeDB match to Validate the XML Results from the TallyEngine
Procedure for XMLPipeDB utility here.
After downloading the application from the XMLPipeDB SourceForge site I moved the .zip into my T drive and extracted it there. I then moved the .jar file into the same directory as my XML file. Then I opened cmd and moved to that directory. I then typed the following command: java -jar xmlpipedb-match-1.1.1.jar "VC_A?[0-9][0-9][0-9][0-9]" < uniprot-organism%3A243277.xml The question mark is included to account for the difference in naming convention. A gene could have the pattern "VC_A[0-9][0-9][0-9][0-9]" or "VC_[0-9][0-9][0-9][0-9]".

Are your results the same as you got for the TallyEngine? Why or why not? Yes they are because I made sure to account for the two different ways a gene could be named. In class we at first got the wrong answer but that was quickly remedied once we figured out this fact.
Using SQL Queries to Validate the PostgreSQL Database Results from the TallyEngine
For more information, see this page.
You can also look for counts at the SQL level, using some variation of a select count(*) query. This requires some knowledge of which table received what data. Here’s an initial tip: the gene/name tags in the XML file land in the genenametype table. A query on this table counting values from this table that were marked as ordered locus in the XML file matching the pattern VC_[0-9][0-9][0-9][0-9] would look like this:
select count(*) from genenametype where type = 'ordered locus' and value ~ 'VC_[0-9][0-9][0-9][0-9]';
In pgAdmin III, you can issue these queries by clicking on the pencil/SQL icon in the toolbar, typing the query into the SQL Editor tab, then clicking on the green triangular Play button to run.

Are your results the same as reported by the TallyEngine? Why or why not?
SQL[edit] You can also look for counts at the SQL level, using some variation of a select count(*) query. This requires some knowledge of which table received what data. Here’s an initial tip: the gene/name tags in the XML file land in the genenametype table. A query on this table counting values from this table that were marked as ordered locus in the XML file matching the pattern VC_[0-9][0-9][0-9][0-9] would look like this: select count(*) from genenametype where type = 'ordered locus' and value ~ 'VC_[0-9][0-9][0-9][0-9]'; In pgAdmin III, you can issue these queries by clicking on the pencil/SQL icon in the toolbar, typing the query into the SQL Editor tab, then clicking on the green triangular Play button to run.
OriginalRowCounts Comparison
Within the .gdb file, look at the OriginalRowCounts table to see if the database has the expected tables with the expected number of records. Compare the tables and records with a benchmark .gdb file.
Benchmark .gdb file: File:Vc-Std External 20101022.gdb
Copy the OriginalRowCounts table from the benchmark and new gdb and paste them here:
Note:
Microsoft Access[edit]
For the GenMAPP Gene Database, you can open the .gdb in Microsoft Access and navigate its tables to find counts for various IDs. Opening the table, noting its size, and doing some sorting may help. You can also look at the OriginalRowCounts table for a summary of totals.
Again, the ideal situation is a correspondence in these numbers with what you found in XML and the relational database.
Visual Inspection
Perform visual inspection of individual tables to see if there are any problems.
- Look at the Systems table. Is there a date in the Date field for all gene ID systems present in the database?
- Open the UniProt, RefSeq, and OrderedLocusNames tables. Scroll down through the table. Do all of the IDs look like they take the correct form for that type of ID?
Note:
.gdb Use in GenMAPP
Note:
Putting a gene on the MAPP using the GeneFinder window
- Try a sample ID from each of the gene ID systems. Open the Backpage and see if all of the cross-referenced IDs that are supposed to be there are there.
Note:
Creating an Expression Dataset in the Expression Dataset Manager
- How many of the IDs were imported out of the total IDs in the microarray dataset? How many exceptions were there? Look in the EX.txt file and look at the error codes for the records that were not imported into the Expression Dataset. Do these represent IDs that were present in the UniProt XML, but were somehow not imported? or were they not present in the UniProt XML?
Note:
Coloring a MAPP with expression data
Note:
Running MAPPFinder
Note:
Compare Gene Database to Outside Resource
The OrderedLocusNames IDs in the exported Gene Database are derived from the UniProt XML. It is a good idea to check your list of OrderedLocusNames IDs to see how complete it is using the original source of the data (the sequencing organization, the MOD, etc.) Because UniProt is a protein database, it does not reference any non-protein genome features such as genes that code for functional RNAs, centromeres, telomeres, etc.
Note:
BIOL 367, Fall 2015, User Page, Team Page
| Weekly Assignments | Individual Journal Pages | Shared Journal Pages |
|---|---|---|
|
|
|
|