Difference between revisions of "Aporras1 Week 14"
From LMU BioDB 2017
(→References: alphabetical order) |
(→Acknowledgements: acknowledging other data analysts) |
||
| Line 121: | Line 121: | ||
==Acknowledgements== | ==Acknowledgements== | ||
| − | #Recieved help from both [[User:Dondi|Dondi]] and [[User:Kdahlquist|Dr. Dahlquist]] from feedback given and instructions given in class. | + | # Recieved help from both [[User:Dondi|Dondi]] and [[User:Kdahlquist|Dr. Dahlquist]] from feedback given and instructions given in class. |
| − | #Copied and modified the instructions from [[Week 10|Week 10]]. | + | # Copied and modified the instructions from [[Week 10|Week 10]]. |
| + | # Texted the data analyst group chat for questions including: [[User:Mbalducc|Mary Balducci]], [[User:dbashour|Dina Bashoura]], and [[User:Emmatyrnauer|Emma Tyrnauer]]. | ||
'''While I worked with the people noted above, this individual journal entry was completed by me and not copied from another source.''' | '''While I worked with the people noted above, this individual journal entry was completed by me and not copied from another source.''' | ||
Revision as of 00:24, 4 December 2017
User page: Antonio Porras
Team page: JASPAR The Friendly Ghost
Assignment page: Week 14
Electronic Lab Notebook
Edits to Week 8 & 10
Made edits in the Week 8 and Week 10 electronic notebooks and journal entries in accordance to the feedback given from Dr. Dahlquist and Dr. Dionisio.
- Edits to: Week 8
- Provided exact formulas used in excel.
- Made sure tense was consistent throughout the electronic notebook.
- Corrected powerpoint provided by supplying correct values.
- Extended concluding paragraph.
- Acknowledged source of data and specified acknowledgements.
- Edits to: Week 10
- Included specific filenames.
- Reported definitions for 6 GO terms.
- Interpreted GO terms in terms of cold shock.
- Updated references to include GO term definitions.
- Updated acknowledgements to specify instructions were copied and modified from Week 10 assignment page.
- Included the excel file used for the stem.
- Included the .txt file that was used for the stem.
- Added summary paragraph to the end of the journal entry.
Using YEASTRACT to Infer which Transcription Factors Regulate a Cluster of Genes
- Opened the gene list in Excel for profile 22 from my stem analysis.
- Gene list Excel file for profile 22 dZAP1: Media:AP dZAP1 profile22 genelist.xlsx
- Copied the list of gene IDs onto my clipboard.
- Launched a web browser and went to the YEASTRACT database.
- On the left panel of the window, clicked on the link to Rank by TF.
- Pasted the list of genes from profile 22 into the box labeled ORFs/Genes.
- Checked the box for Check for all TFs.
- Accepted the defaults for the Regulations Filter (Documented, DNA binding plus expression evidence)
- Did not apply a filter for "Filter Documented Regulations by environmental condition".
- Ranked genes by TF using: The % of genes in the list and in YEASTRACT regulated by each TF.
- Clicked the Search button.
- Questions:
- How many transcription factors are green or "significant"?
- 49 transcription factors are green or significant.
- 13 transcription factors are yellow or borderline significant.
- 125 transcription factors are pink or insignificant.
- Copied the table of results from the web page and pasted it into a new Excel workbook.
- Uploaded the Excel file and saved it as "AP YEASTRACT Transcription Factors"
- Is dZAP1 transcription factor on the list? If so, what is their "% in user set", "% in YEASTRACT", and "p value".
- dZAP1p is on the list.
- 43.03% in user set
- 7.02% in YEASTRACT
- p-value: 2E-15
- dZAP1p is on the list.
- Chose the listed transcription factors from the 49 "significant" TFs and selected 20 with the highest value of "% in user set" because they target a high percentage of the genes within my dataset. Also included two transcription factors, GLN3 & HAP4 as directed by the Week 10 instructions. List of "significant" transcription factors used to run the model:
- GLN3
- HAP4
- Ace2p
- Sfp1p
- Bas1p
- Msn2p
- Yap1p
- Ash1p
- Gcn4p
- Msn4p
- Abf1p
- Cst6p
- Sok2p
- Rpn4p
- Hsf1p
- Zap1p
- Cin5p
- Aft1p
- Spt23p
- Pdr1p
- Met4p
- Arr1p
- Went back to the YEASTRACT database and followed the link to Generate Regulation Matrix.
- Copied and pasted the list of transcription factors I identified above into both the "Transcription factors" field and the "Target ORF/Genes" field.
- Used the "Regulations Filter" options of "Documented", "Only DNA binding evidence"
- Clicked the "Generate" button.
- In the results window that appeared, clicked on the link to the "Regulation matrix (Semicolon Separated Values (CSV) file)" that appeared and saved it to my Desktop.
- Uploaded file to wiki as: Media:AP Regulation Matrix profile22 dZAP1.xlsx
- How many transcription factors are green or "significant"?
Visualizing Your Gene Regulatory Networks with GRNsight
- Opened the file, Media:AP Regulation Matrix profile22 dZAP1.xlsx, in Excel.
- Fixed formatting:
- Selected the entire Column A. Then went to the "Data" tab and selected "Text to columns". In the Wizard that appears, selected "Delimited" and clicked "Next". In the next window, selected "Semicolon", and clicked "Next". In the next window, left the data format at "General", and clicked "Finish".
- Known as an "adjacency matrix." If there is a "1" in the cell, that means there is a connection between the trancription factor in that row with that column.
- Saved this file in Microsoft Excel workbook format (.xlsx).
- YEASTRACT Adjacency Matrix: Media:AP Adjacency Matrix profile22 dZAP1.xlsx
- Checked to see that all of the transcription factors in the matrix are connected to at least one of the other transcription factors by making sure that there was at least one "1" in a row or column for that transcription factor.
- No transcription factors were deleted as all had at least "1" in a row or column for that transcription factor.
- Inserted a new worksheet into the Excel file, Media:AP Adjacency Matrix profile22 dZAP1.xlsx. and named it "network". Went back to the previous sheet and selected the entire matrix and copied it. Went to the new worksheet and clicked on the A1 cell in the upper left. Selected "Paste special" from the "Home" tab. In the window that appears, checked the box for "Transpose".
- Delete the "p" from each of the gene names in the columns. Adjusted the case of the labels to make them all upper case.
- In cell A1, copied and pasted the text "rows genes affected/cols genes controlling".
- Alphabetization:
- Selected the area of the entire adjacency matrix.
- Clicked the Data tab and clicked the custom sort button.
- Sorted Column A alphabetically, excluding the header row.
- Sorted row 1 from left to right, excluding cell A1. In the Custom Sort window, clicked on the options button and select sort left to right, excluding column 1.
- Named the worksheet containing your organized adjacency matrix "network" and Save.
- Now we will visualize what these gene regulatory networks look like with the GRNsight software.
- Go to the GRNsight home page.
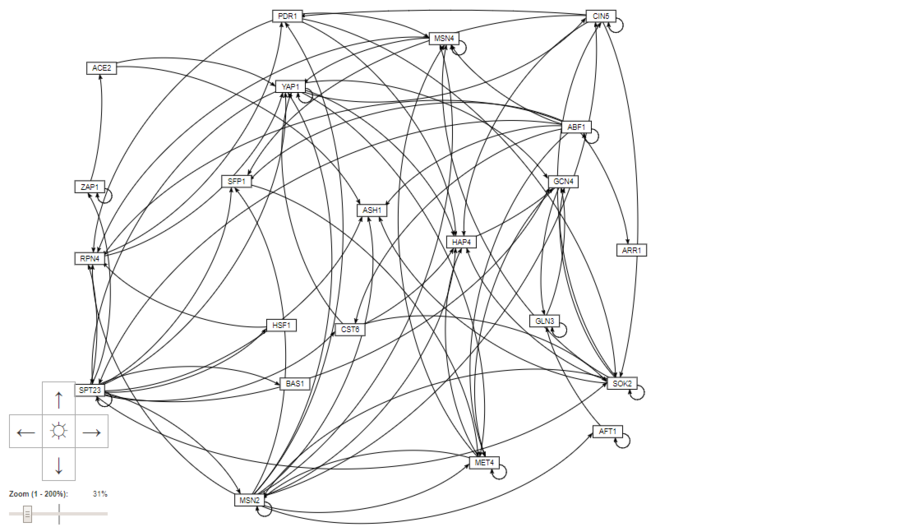
- Select the menu item File > Open and select the regulation matrix .xlsx file that has the "network" worksheet in it that you formatted above. If the file has been formatted properly, GRNsight should automatically create a graph of your network. Move the nodes (genes) around until you get a layout that you like and take a screenshot of the results. Paste it into your PowerPoint presentation.
Summary of what you need to turn in for the individual Week 10 assignment
- Your individual journal page should have an electronic lab notebook recording your work. This includes the detailed methods specific to your analysis, your result files, the answers to any questions posed in the protocol above, a scientific conclusion, and the acknowledgments and references sections. Don't forget your paragraph which is a biological interpretation of your stem results.
- Upload your updated Excel spreadsheet to the wiki that has today's manipulations in it. Use the same filename as before so that the download link that you already (previous versions will still be available in the history).
- Append the screenshots of the stem results to the PowerPoint presentation that contains the p value table that you created for the Week 8 assignments. Each slide in the presentation should have a meaningful title that describes the main message of the slide.
- Zip together all of the tab-delimited text files that you created for and from stem and upload them to the wiki.
- the file that was saved from your original spreadsheet that you used to run stem
- each of the genelist and GOlist files for each of your significant profiles.
- Write a paragraph-length conclusion for this week's exercise.
Deliverables
- YEASTRACT Transcription Factor Data: Media:AP YEASTRACT Transcription Factors.xlsx
- YEASTRACT Regulation Matrix Profile: Media:AP Regulation Matrix profile22 dZAP1.xlsx
- YEASTRACT Adjacency Matrix: Media:AP Adjacency Matrix profile22 dZAP1.xlsx
- YEASTRACT Adjacency Matrix with Network for GRNsight: Media:AP Adjacency Matrix profile22 Network dZAP1.xlsx
- Screenshot of GRNsight Regulatory Network:

Acknowledgements
- Recieved help from both Dondi and Dr. Dahlquist from feedback given and instructions given in class.
- Copied and modified the instructions from Week 10.
- Texted the data analyst group chat for questions including: Mary Balducci, Dina Bashoura, and Emma Tyrnauer.
While I worked with the people noted above, this individual journal entry was completed by me and not copied from another source.
Aporras1 (talk) 16:53, 28 November 2017 (PST)
References
- Dahlquist, K. D., Dionisio, J. D. N., Fitzpatrick, B. G., Anguiano, N. A., Varshneya, A., Southwick, B. J., & Samdarshi, M. (2016). GRNsight: a web application and service for visualizing models of small-to medium-scale gene regulatory networks. PeerJ Computer Science, 2, e85.
- LMU BioDB 2017. (2017). Week 14. Retrieved November 28, 2017, from https://xmlpipedb.cs.lmu.edu/biodb/fall2017/index.php/Week_14
- LMU BioDB 2017. (2017). Week 8. Retrieved November 29, 2017, from https://xmlpipedb.cs.lmu.edu/biodb/fall2017/index.php/Week_8
- LMU BioDB 2017. (2017). Week 10. Retrieved November 29, 2017, from https://xmlpipedb.cs.lmu.edu/biodb/fall2017/index.php/Week_10
- Teixeira, M. C., Monteiro, P. T., Guerreiro, J. F., Gonçalves, J. P., Mira, N. P., dos Santos, S. C., ... & Madeira, S. C. (2013). The YEASTRACT database: an upgraded information system for the analysis of gene and genomic transcription regulation in Saccharomyces cerevisiae. Nucleic acids research, 42(D1), D161-D166.