Kmill104 Week 10
- Analyzing and Interpreting STEM Results
- Select one of the profiles you saved in the previous step for further intepretation of the data. I suggest that you choose one that has a pattern of up- or down-regulated genes at the cold shock timepoints. Each member of your group should choose a different profile. Answer the following:
- Why did you select this profile? In other words, why was it interesting to you? I chose the 45 profile. This was most interesting to me because it was the most significant profile, and the up-regulation occurs early and then drops.
- How many genes belong to this profile? 549.0
- How many genes were expected to belong to this profile? 47.1
- What is the p value for the enrichment of genes in this profile? 1.00
- Bear in mind that we just finished computing p values to determine whether each individual gene had a significant change in gene expression at each time point. This p value determines whether the number of genes that show this particular expression profile across the time points is significantly more than expected.
- Open the GO list file you saved for this profile in Excel. This list shows all of the Gene Ontology terms that are associated with genes that fit this profile. Select the third row and then choose from the menu Data > Filter > Autofilter. Filter on the "p-value" column to show only GO terms that have a p value of < 0.05. How many GO terms are associated with this profile at p < 0.05? 81
- The GO list also has a column called "Corrected p-value". This correction is needed because the software has performed thousands of significance tests. Filter on the "Corrected p-value" column to show only GO terms that have a corrected p value of < 0.05. How many GO terms are associated with this profile with a corrected p value < 0.05? 11
- Select 6 Gene Ontology terms from your filtered list (either p < 0.05 or corrected p < 0.05).
- cytoplasmic exosome (RNase complex) (GO:0000177)
- nucleic acid binding (GO:0003676)
- ribosomal large subunit export from nucleus (GO:0000055)
- snoRNA binding (GO:0030515)
- mitochondrial translation (GO:0032543)
- nuclear polyadenylation-dependent rRNA catabolic process (GO:0071035)
- Each member of the group will be reporting on his or her own cluster in your research presentation. You should take care to choose terms that are the most significant, but that are also not too redundant. For example, "RNA metabolism" and "RNA biosynthesis" are redundant with each other because they mean almost the same thing.
- Note whether the same GO terms are showing up in multiple clusters.
- Look up the definitions for each of the terms at http://geneontology.org. In your journal entry, will discuss the biological interpretation of these GO terms. In other words, why does the cell react to cold shock by changing the expression of genes associated with these GO terms? Also, what does this have to do with the transcription factor being deleted (for the groups working with deletion strain data)? I'm not completely sure why these specific genes had a change in expression, but I noticed that the genes were concerned with regulating RNA and protein production from mRNA. When cold shock is experienced by the cell, there likely needs to be a change in what mRNA is transcribed and at what rate. Additionally, the formation of proteins and the rate at which they are formed must also be regulated. Second question is not related to the wild type strain
- To easily look up the definitions, go to http://geneontology.org.
- Copy and paste the GO ID (e.g. GO:0044848) into the search field on the left of the page.
- In the results page, click on the button that says "Link to detailed information about <term>, in this case "biological phase"".
- The definition will be on the next results page, e.g. here.
- definition of cytoplasmic exosome (RNase complex) (GO:0000177): A ribonuclease complex that has 3-prime to 5-prime processive hydrolytic exoribonuclease activity producing 5-prime-phosphomonoesters. Participates in a multitude of cellular RNA processing and degradation events preventing nuclear export and/or translation of aberrant RNAs. Restricted to processing linear and circular single-stranded RNAs (ssRNA) only. RNAs with complex secondary structures may have to be unwound or pre-processed by co-factors prior to entering the complex, esp if the 3-prime end is structured.
- nucleic acid binding (GO:0003676): Binding to a nucleic acid.
- ribosomal large subunit export from nucleus (GO:0000055): The directed movement of a ribosomal large subunit from the nucleus into the cytoplasm.
- snoRNA binding (GO:0030515): Binding to a small nucleolar RNA.
- mitochondrial translation (GO:0032543): The chemical reactions and pathways resulting in the formation of a protein in a mitochondrion. This is a ribosome-mediated process in which the information in messenger RNA (mRNA) is used to specify the sequence of amino acids in the protein; the mitochondrion has its own ribosomes and transfer RNAs, and uses a genetic code that differs from the nuclear code.
- nuclear polyadenylation-dependent rRNA catabolic process (GO:0071035) : The chemical reactions and pathways occurring in the nucleus and resulting in the breakdown of a ribosomal RNA (rRNA) molecule, including RNA fragments released as part of processing the primary transcript into multiple mature rRNA species, initiated by the enzymatic addition of a sequence of adenylyl residues (polyadenylation) at the 3' end the target rRNA.
- Select one of the profiles you saved in the previous step for further intepretation of the data. I suggest that you choose one that has a pattern of up- or down-regulated genes at the cold shock timepoints. Each member of your group should choose a different profile. Answer the following:
Stopping point for Thursday's lab. Be sure to upload all of the files requested to your Week 10 individual journal entry by 12:01am on Tuesday, March 26 so that the files can be checked before we do the next step on Tuesday. Also invoke your template on your Week 10 individual journal entry right away.
Contents
- 1 Using YEASTRACT to Infer which Transcription Factors Regulate a Cluster of Genes (Tuesday, March 26)
- 2 Creating and Visualizing Your Gene Regulatory Network with GRNsight (Tuesday, March 26)
- 3 Creating the GRNmap Input Workbook (Tuesday, March 26)
- 4 User Page
- 5 Assignment Pages
- 6 Individual Journal Entry Pages
- 7 Shared Journal Entry Pages
Using YEASTRACT to Infer which Transcription Factors Regulate a Cluster of Genes (Tuesday, March 26)
In the previous analysis using STEM, we found a number of gene expression profiles (aka clusters) which grouped genes based on similarity of gene expression changes over time. The implication is that these genes share the same expression pattern because they are regulated by the same (or the same set) of transcription factors. We will explore this using the YEASTRACT database.
- Open the gene list in Excel for the one of the significant profiles from your stem analysis that you chose to perform your GO analysis. It should be a cluster with a clear cold shock/recovery up/down or down/up pattern, and should be one of the largest clusters.
- Copy the list of gene IDs onto your clipboard.
- Launch a web browser and go to the YEASTRACT database.
- On the left panel of the window, click on the link to Rank by TF.
- Paste your list of genes from your cluster into the box labeled ORFs/Genes.
- Check the box for Check for all TFs.
- Accept the defaults for the Regulations Filter (Documented, DNA binding or expression evidence)
- Do not apply a filter for "Filter Documented Regulations by environmental condition".
- Rank genes by TF using: The % of genes in the list and in YEASTRACT regulated by each TF.
- Click the Search button.
- Answer the following questions:
- In the results window that appears, the p values colored green are considered "significant", the ones colored yellow are considered "borderline significant" and the ones colored pink are considered "not significant". How many transcription factors are green or "significant"? 33
- Copy the table of results from the web page and paste it into a new Excel workbook to preserve the results.
- Copy by selecting and dragging down on the table.
- When pasting into Excel, remember to Paste special > Paste values.
- Upload the Excel file to the wiki and link to it in your electronic lab notebook.
- Are CIN5 or GLN3 on the list? If so, what is their "% in user set", "% in YEASTRACT", and "p value"?
- CIN5 - % in user set: 30.63%, % in scerevisiae: 7.22%, p-value: 0.522044721
- GLN3 - % in user set: 38.38%, % in scerevisiae: 8.46%, p-value: 0.002604838
Creating and Visualizing Your Gene Regulatory Network with GRNsight (Tuesday, March 26)
For the mathematical model that we will build, we need to define a gene regulatory network of transcription factors that regulate other transcription factors. We can use GRNsight to assist us with creating the network. We want to generate a network with approximately 15-20 connected transcription factors in it.
- You need to select from the list of "significant" transcription factors that you found in YEASTRACT, which ones you will use to run the model. You will use these transcription factors and add GLN3 and CIN5 if they are not in your list.
- Generally, you should include the top transcription factors with the smallest p values. Explain in your electronic notebook how you decided on which transcription factors to include. Record the list and your justification in your electronic lab notebook. Each group member will select a different network (they can have some overlapping transcription factors, but some should also be different).
- Go to the GRNsight beta website.
- Under the "Network" panel on the left-hand side, click the button "Load from database".
- Type the standard name of the transcription factor in the "Select gene" field and click the find button (magnifying glass).
- Continue to add transcription factors in this way until you have added 15-20.
- Click the "Generate Network" button.
- Your network should appear on the screen.
- Check to see if all of the rectangular boxes (nodes) are connected by at least one arrow to another node. If there is a node that is not connected, go back to the "Load from database" button and select your transcription factors again, leaving out the node that was disconnected.
- Record in your electronic lab notebook the number of genes and edges in your network (found at the upper right of the menu bar). 20 genes, 37 edges
- Under the "Layout" section, click on the "Grid Layout" button.
- Export the network image by going to the Export menu and selecting "Export Image > To PNG". Upload the file to the wiki and display it on your individual journal page.
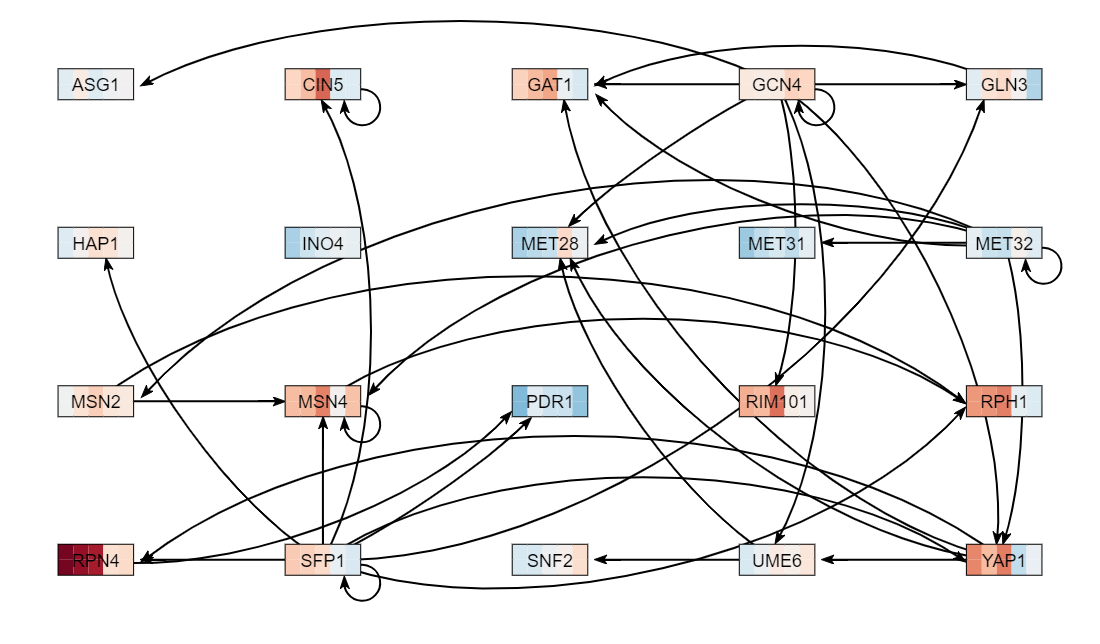
- Export the network image by going to the Export menu and selecting "Export Image > To PNG". Upload the file to the wiki and display it on your individual journal page.

Creating the GRNmap Input Workbook (Tuesday, March 26)
We will also use GRNsight to automatically generate the input workbook for the GRNmap modeling software. Note that this feature is still under development, and we will be performing quality control on the exported workbook.
- With your final network still open in GRNsight, select from the Export menu "Export Data > To Excel". In the window that appears, select the following:
- Under "Select the Expression Data Source:", choose "Dahlquist_2018"
- Under "Select Workbook Sheets to Export:", select the following:
- Network sheets
- "network"
- Expression sheets
- dcin5_log2_expression
- dgln3_log2_expression
- wt_log2_expression
- Additional sheets
- "degradation_rates"
- "optimization_parameters"
- "production_rates"
- "threshold_b"
- Network sheets
- Click the "Export Workbook" button.
- Open your workbook in Excel to perform quality control. Check that it has the following sheets with the following content:
- The "network" sheet should have an adjacency matrix with your selected regulatory transcription factors across the top row and in the first column.
- The "dcin5_log2_expression", "dgln3_log2_expression", and "wt_log2_expression" sheets should have log2 fold changes for each of your selected regulatory transcription factors for each time point (15, 30, 60, 90, 120). Replicate values have the same column headers. If a particular gene is missing all 4-5 replicate values at a particular timepoint for a particular strain, we need to exclude it from the analysis. Go back to generating your network and repeat the steps to generate the network and export to Excel without that gene. Record this in your electronic lab notebook.
- The "production_rates" and "degradation_rates" sheets should have values for each gene.
- The "threshold_b" sheet should have a value of 0 for each gene.
- In the "optimization_parameters" sheet, change the "alpha" value to 0.02 instead of 0.002.
- Insert a new worksheet and name it "network_weights".
- Copy the entire content of the "network" sheet into the "network_weights" sheet.
- Save and upload your Excel Workbook to the wiki and link to it on your individual journal page. Dr. Dahlquist will run your input workbook in the GRNmap modeling software over the break.
Stopping point for Tuesday, March 26. Be sure to complete up to this point for the interim deadline of 11:59pm on Tuesday, April 2 so your files can be checked before class.
User Page
Assignment Pages
- Week 1
- Week 2
- Week 3
- Week 4
- Week 5
- Week 6
- Week 8
- Week 9
- Week 10
- Week 11
- Week 12
- Week 13
- Week 14
- Week 15
Individual Journal Entry Pages
- Kmill104 Week 1
- Kmill104 Week 2
- MSymond1 KMill104 Week 3
- Monarch Initiative Week 4
- Kmill104 Week 5
- Kmill104 Week 6
- Kmill104 Week 8
- Kmill104 Week 9
- Kmill104 Week 10
- Kmill104 Week 11
- Kmill104 Week 12
- Data Analysts Week 13
- Data Analysts Week 14
- Data Analysts Week 15