Taur.vil Week 9
Week 9 Individual Journal
Digital Notebook
Downloading , importing, and exporting
- Downloaded GenMAPP Builder 2.0b70 and SMLPipeDB-Match-1.1.1
- Uniprot file for VC was downloaded and saved as VC_2013_10_22_TVKS.xml
- GOA file was saved as 46.V_cholerae_ATCC_39315_TVKS_2013_10_22.goa
- Direct download from wiki due to network connectivity problems.
- Downloaded GO OBO-SML and saved as Go_daily-termdb_TVKS_2013_10_22.obo-xml.gz
- Done using beta page and legacy download
- Opened PgAdminIII
- Logged into postgres and created new database titled VC_TVKS_2013_10_22_gmb2b70
- Used postgres function to open gmbuilder.sql in the GenMAPP Builder folder
- executed command to create tables in database
- Verified that 159 tables were created
- Launced gmbuilder-32bit.bat from the GenMAPP Builder download folder
- Configured database to connect to postgres on the local computer
- Imported UniProt XML, GO OBO-XML, and GOA data files.
- Processed GO data after it was imported
- Exported a GenMAPP database: Vc-Std 20131022 TVKS gmb2b70.gdb
Testing the Data Feed
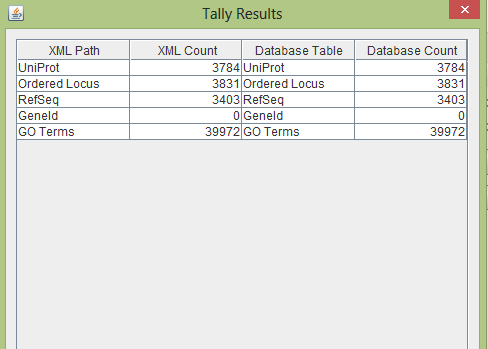
- Ran tally engine in GenMAPP Builder to compare XML file and the database. The two matched.
- Ran XMLPipeDB Match in the command prompt
- Cd'd into folder on desktop for databases
- Ran the following two commands to count all ordered loci. The first did not detect those with the optional A after the underscore.
- "\Program Files <x86>\Java]jre7\bin\java" -jar xmlpipe-db-match-1.1.1.jar "VC_[0-9][0-9][0-9][0-9]" < VC_2013_20_22TVKS.xml
- "\Program Files <x86>\Java]jre7\bin\java" -jar xmlpipe-db-match-1.1.1.jar "VC_(A|)[0-9][0-9][0-9][0-9]" < VC_2013_20_22TVKS.xml
- Results matched those of the TallyEngine.
- Used SQL to search through the filled data tables using the command bellow. Found the same amount as the other two methods.
- select count (*) when type='ordered locus' and value ~ 'VC_(A|)[0-9][0-9][0-9][0-9]'
- Opened the gdb file exported earlier in Microsoft Access
- Ordered Locus value was one higher than expected based on the prior data.
- explained by GenMAPP splitting apart a conjoined pair of genes
- VC_1738 and VC_1739 were linked together and not identified as separate genes by the other methods
Export Information
Version of GenMAPP Builder: 2.0b70
Computer on which export was run:BIOL 206, back right
- Then my personal lab top
Postgres Database name: VC_TVKS_2013_10_22_gmb2b70
UniProt XML filename: VC_2013_10_22_TVKS.xml
- UniProt XML version (The version information can be found at the UniProt News Page):
- Time taken to import: 8.31 minutes (4.55 on own computer)
GO OBO-XML filename: go_daily-termdb_TVKS_2013_10_22.obo-xml
- GO OBO-XML version (The version information can be found in the file properties after the file downloaded from the GO Download page has been unzipped):
- Time taken to import: 9.11 minutes on own computer
- Time taken to process: 7.60 min on own computer
GOA filename: 46.V_cholerae_ATCC_39315_TVKS_2013_10_22.goa
- GOA version (News on this page records past releases; current information can be found in the Last modified field on the FTP site):
- Time taken to import: 0.08 minutes
Name of .gdb file:
- Time taken to export .gdb:~3 hours
- started at 20:15, finished by 23:30
- Upload your file and link to it here. gdb export file
Note: Initially attempted on lab computer, but it was too slow and I switched to my own computer that evening.My personal computer was used for the rest of the week's analysis.
TallyEngine
Run the TallyEngine in GenMAPP Builder and record the number of records for UniProt and GO in the XML data and in the PostgreSQL databases (or you can upload and link to a screenshot of the results).
Tally verified expected results, the XML count matched the database count: 
Using XMLPipeDB match to Validate the XML Results from the TallyEngine
Follow the instructions found on this page to run XMLPipeDB match.
Are your results the same as you got for the TallyEngine? Why or why not?
Using XMLPipeDB Match, we initially found 2738 ordered loci using the first code listed bellow. However, when the command was changed to included VCA files (second bit of code), the actual results matched the expected at 3831.
"\Program Files <x86>\Java]jre7\bin\java" -jar xmlpipe-db-match-1.1.1.jar "VC_[0-9][0-9][0-9][0-9]" < VC_2013_20_22TVKS.xml
"\Program Files <x86>\Java]jre7\bin\java" -jar xmlpipe-db-match-1.1.1.jar "VC_(A|)[0-9][0-9][0-9][0-9]" < VC_2013_20_22TVKS.xml
Note: needed to include the full extension of java due to technicalities in the Win8 system.
Using SQL Queries to Validate the PostgreSQL Database Results from the TallyEngine
Follow the instructions on this page to query the PostgreSQL Database.
Our SQL query (bellow), found the expected 3831 ordered loci.
select count (*) when type='ordered locus' and value ~ 'VC_(A|)[0-9][0-9][0-9][0-9]'
OriginalRowCounts Comparison
Within the .gdb file, look at the OriginalRowCounts table to see if the database has the expected tables with the expected number of records. Compare the tables and records with a benchmark .gdb file.
Benchmark .gdb file: (for the Week 9 Assignment, use the "Vc-Std_External_20101022.gdb" as your benchmark, downloadable from here.
Copy the OriginalRowCounts table and paste it here: My newly formed gdb
- Table Rows
- Info 1
- Systems 30
- Relations 18
- Other 0
- GeneOntologyTree 97982
- GeneOntology 5556
- UniProt-GOCount 3240
- GeneOntologyCount 3239
- UniProt-GeneOntology 20464
- UniProt 3784
- Pfam 2102
- RefSeq 3403
- PDB 223
- InterPro 4349
- OrderedLocusNames 3832
- EMBL 228
- UniProt-EMBL 5452
- UniProt-OrderedLocusNames 3832
- UniProt-PDB 319
- UniProt-InterPro 10393
- UniProt-RefSeq 3635
- UniProt-Pfam 4648
- RefSeq-Pfam 4145
- RefSeq-InterPro 9241
- RefSeq-PDB 234
- RefSeq-OrderedLocusNames 3520
- RefSeq-EMBL 3669
- OrderedLocusNames-Pfam 4367
- OrderedLocusNames-InterPro 9723
- OrderedLocusNames-PDB 235
- OrderedLocusNames-EMBL 4111
- RefSeq-GeneOntology 18931
- OrderedLocusNames-GeneOntology 20613
Vc_External: Dowloaded gdb
- Table Rows
- Info 1
- Systems 30
- Relations 26
- Other 0
- GeneOntologyTree 35314
- GeneOntology 3829
- UniProt-GOCount 2467
- GeneOntologyCount 2466
- UniProt-GeneOntology 13289
- UniProt 3784
- Pfam 1955
- RefSeq 3827
- GeneId 3827
- PDB 157
- InterPro 3942
- OrderedLocusNames 7664
- EMBL 293
- UniProt-EMBL 5742
- UniProt-OrderedLocusNames 7664
- UniProt-PDB 243
- UniProt-InterPro 9565
- UniProt-GeneId 4125
- UniProt-RefSeq 4125
- UniProt-Pfam 4601
- RefSeq-Pfam 4263
- RefSeq-GeneId 3971
- RefSeq-InterPro 8840
- RefSeq-PDB 169
- RefSeq-OrderedLocusNames 7942
- RefSeq-EMBL 4260
- GeneId-Pfam 4263
- GeneId-InterPro 8840
- GeneId-PDB 169
- GeneId-OrderedLocusNames 7942
- GeneId-EMBL 4260
- OrderedLocusNames-Pfam 8538
- OrderedLocusNames-InterPro 17712
- OrderedLocusNames-PDB 338
- OrderedLocusNames-EMBL 8540
- GeneId-GeneOntology 13332
- RefSeq-GeneOntology 13332
- OrderedLocusNames-GeneOntology 26702
Note: The downloaded database had more table entries than my database. In almost all cases, the values between the two databases were unequal, generally with the newer dataset (the one I made) having more examples. Interestingly, 3832 ordered locus names were found in this analysis instead of 3831. This is because GenMappBuilder has code to split compound names such as VC_1738/VC1739 which were combined in the original sheets. This explains how row counts appear different in the gdb than in the other methods.
(second note: doing an SQL or xmlPipeDB-match search for VC_(A|)[0-9][0-9][0-9][0-9]/VC_(A|)[0-9][0-9][0-9][0-9] finds one match, the linked genes that are split apart by genMAPP)
Visual Inspection
Perform visual inspection of individual tables to see if there are any problems.
- Look at the Systems table. Is there a date in the Date field for all gene ID systems present in the database?
- In the systems table there are not date field's for all gene ID systems in the database.
- Open the UniProt, RefSeq, and OrderedLocusNames tables. Scroll down through the table. Do all of the IDs look like they take the correct form for that type of ID?
- The IDs have some minor differences between them. All the IDs produced by GenMAPP have an underscore, but that is not present in some of the other formats such as UniProt.
Compare Gene Database to Outside Resource
The OrderedLocusNames IDs in the exported Gene Database are derived from the UniProt XML. It is a good idea to check your list of OrderedLocusNames IDs to see how complete it is using the original source of the data (the sequencing organization, the MOD, etc.) Because UniProt is a protein database, it does not reference any non-protein genome features such as genes that code for functional RNAs, centromeres, telomeres, etc.
Note: The ordered names seem to make general sense. I am a bit confused what some parts of the procedure did, but feel I can work through it again and learn more about it doing the group projects when the example is not spoon fed to us in class.
Personal Template
- As part of Biological Databases
Please Remember the Harassing of Deities is Strictly Prohibited
Never Forget Samson