GÉNialOMICS Gene Database Testing Report (Initial Export)
Contents
- 1 Export Information
- 2 Using TallyEngine
- 3 Using XMLPipeDB match to Validate the XML Results from the TallyEngine
- 4 Using SQL Queries to Validate the PostgreSQL Database Results from the TallyEngine
- 5 OriginalRowCounts Comparison
- 6 Visual Inspection
- 7 .gdb Use in GenMAPP
- 8 Compare Gene Database to Outside Resource
Export Information
Version of GenMAPP Builder: 3.0.0-build-5
Computer on which export was run: Home Workstation
Postgres Database name: B.cenocepacia_J2315_20151119_gmb3build5
UniProt XML filename: uniprot-taxonomy%3A216591_GEN_BL12_20151119.xml
- UniProt XML version: UniProt release 2015_11 - November 11, 2015
- UniProt XML download link: UniProtKB link for the complete proteome of J2315
- Time taken to import: 3.40 minutes
- Note: No issues were found with the import of this file.
GO OBO-XML filename: go_daily-termdb_GEN_BL12_20151119.obo-xml
- GO OBO-XML version (derived from the date modified on the file, itself): Date Modified: 11/19/2015 2:24 AM
- GO OBO-XML download link: Link from GO website
- Time taken to import: 5.23 minutes
- Time taken to process: 3.83 minutes
- Note: No issues were found with the import of this file.
GOA filename: 31277.B_cepacia_GEN_BL12_20151119.goa
- GOA version: Date Modified: 11/10/15, 1:47:00 PM (information sourced from FTP site)
- GOA download link: FTP site file
- Time taken to import: 0.04 Minutes
- Note: No issues were found with the import of this file.
Name of .gdb file: Bc-Std_GEN_BL12_20151119.gdb
- Time taken to export: 2 hour 29 minutes
- Start time: 6:31
- End time: 9:00
Note: File was exported without any major issues, however, the export appeared to take considerably longer than the one that was conducted for Vibrio cholerae (took more than an hour longer). Possible explanations include the fact that: B. cenocepacia strain J2315 has a larger proteome/genome (6993 proteins associated with J2315 proteome, compared to the 3784 of V. cholerae), a different computer was utilized for the export (Home Workstation instead of the Seaver 120 Workstation). GenMAPP builder is also not modified to specifically work with the J2315 genes/IDs; this could have also impacted the time that it took for the export to complete. It was also noticed that the produced .gdb file was smaller than the one that was created for V. cholerae.
Using TallyEngine
- PostgreSQL was initialized through pgAdmin III and the database B.cenocepacia_J2315_20151119_gmb3build5 was left running
- GenMAPP builder was booted and Run XML and Database Tallies for UniProt and GO was selected under the Tallies menu item; the UniProt XML and GO files that were imported were chosen
- Results of TallyEngine:
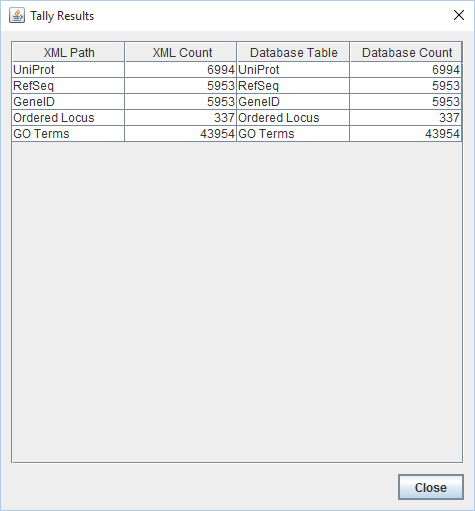
- Note: UniProt, RefSeq, GeneID, GO Terms, and Ordered Locus counts in the XML matched the ones in the Postgres database. RefSeq counts matched those of GeneID. Only 337 Ordered Locus counts were identified in the XML and the database (appears to be very low considering that each coding sequence has its own OrderedLocusName). It appears that all data was successfully imported except the Ordered Locus names (it appears that the import did not proceed correctly and it appears that genMAPP builder is not identifying some data within the XML file; a modification of the program could fix this)
.png)
Using XMLPipeDB match to Validate the XML Results from the TallyEngine
- The Windows command line was launched (cmd.exe)
- This set of commands was inputted into the command line in order to utilize XMLPipeDB match to verify the OrderedLocusNames count:
java -jar xmlpipedb-match-1.1.1.jar "p?BCA[A-Z]?[0-9][0-9][0-9][A-Z]?[0-9]?[A-Z, a-z]?" < uniprot-taxonomy%3A216591_GEN_BL12_20151119.xml- This command was created with the found gene patterns in mind; the patterns are further explained in the Week 12 journal
- NOTE: Prior to executing the command, the folder that held the files and xmlpipedb-match-1.1.1.jar was entered through the Windows command line (a set of CD commands was used in order to enter the correct directory)
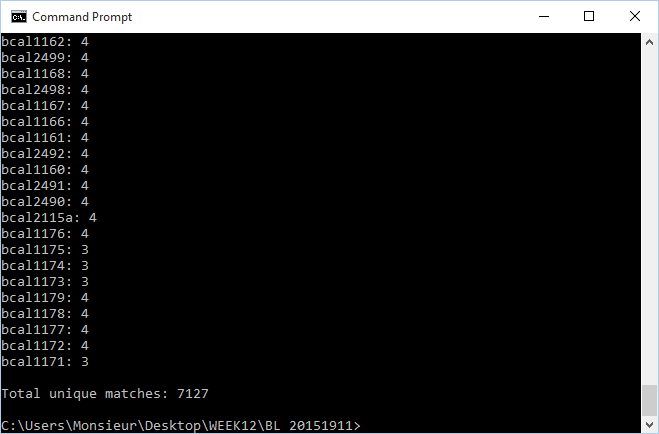
- 7127 unique matches were found through XMLPipeDB match

Are your results the same as you got for the TallyEngine? Why or why not?
- These results are very different from what was found through TallyEngine. TallyEngine reported 337 items for OrderedLocusNames while 7127 matches were found through the Match command. The large difference lends more weight to the possibility that GenMAPP builder is not recognizing most of the terms as OrderedLocusNames.
Using SQL Queries to Validate the PostgreSQL Database Results from the TallyEngine
- pgAdmin III was booted and all of the necessary connections were made
- It was realized that the gene/name tags in the XML file end up in the genenametype table (source: the wiki page regarding database quality analysis
- In pgAdmin III, the query
select count(*) from genenametype where type = 'ordered locus' and value ~ 'p?BCA[A-Z]?[0-9][0-9][0-9][A-Z]?[0-9]?[A-Z, a-z]?';was issued via the SQL Query menu in order to validate the PostgreSQL Database Results according to TallyEngine- 0 unique matches were found in pgAdmin III (postgres database results). It is possible that the command was not interpreted properly by PSQL but it also a possibility that the import did not proceed properly and the tables were not fully populated with all of the OrderedLocusNames present in the XML.
select count(*) from genenametype where type = 'ordered locus'was executed as a query to verify, oncemore, the entries present in the genenametype table- A count of 337 was given, which is the same number that was found through TallyEngine
select * from genenametype where type = 'ordered locus'was executed in order to take a look at the rows/columns that are within the GeneNameType table
- It was noticed that the OrderedLocusNames values are not in the format that was being tested for earlier. The format is
BceJ2315_#####<code> instead of <code>p?BCA[A-Z]?[0-9][0-9][0-9][A-Z]?[0-9]?[A-Z, a-z]?; these two formats are discussed in the Week 12 Assignment
- It was noticed that the OrderedLocusNames values are not in the format that was being tested for earlier. The format is

Are your results the same as reported by the TallyEngine? Why or why not?
- These results are the same as reported by the TallyEngine, however, it seems that these results are not indicative of a proper data import. It appears that most of the data tied to other orderedlocusnames formats was not imported into the database and was not taken into account by TallyEngine.
- Further match testing was also conducted through the use of
java -jar xmlpipedb-match-1.1.1.jar "BceJ2315_[0-9][0-9][0-9][0-9][0-9]?" < uniprot-taxonomy%3A216591_GEN_BL12_20151119.xmlwith the windows command line. This command yielded 338 results which is one off from what was seen with TallyEngine and the SQL queries; it also suggests that only the "BceJ2315_#####" data was imported (most of the data is tied to the other gene name format)
- Further match testing was also conducted through the use of
OriginalRowCounts Comparison
Within the .gdb file, look at the OriginalRowCounts table to see if the database has the expected tables with the expected number of records. Compare the tables and records with a benchmark .gdb file.
Benchmark .gdb file:
Copy the OriginalRowCounts table from the benchmark and new gdb and paste them here:
Note:
Visual Inspection
Perform visual inspection of individual tables to see if there are any problems.
- Look at the Systems table. Is there a date in the Date field for all gene ID systems present in the database?
- Open the UniProt, RefSeq, and OrderedLocusNames tables. Scroll down through the table. Do all of the IDs look like they take the correct form for that type of ID?
Note:
.gdb Use in GenMAPP
Note:
Putting a gene on the MAPP using the GeneFinder window
- In the main GenMAPP Drafting Board window, left-click on the icon for "Gene" in the upper left corner of the window. Click on the Drafting Board to place the Gene on the MAPP. Now, right-click on the gene to access the GeneFinder window. Type or paste a gene ID into the Gene ID field. Select the appropriate Gene ID system from the drop-down menu and click the Search button. For example, for Vibrio cholerae, you could search for the ID "VC0028", which is an OrderedLocusNames ID. Once the ID has been found, click the OK button to return to the Drafting Board window.
- For the Final Project, you will need to try a sample ID from each of the gene ID systems, not just OrderedLocusNames.
- Open the Backpage by left-clicking on the gene box on the Drafting Board to see if all of the cross-referenced IDs that are supposed to be there are there.
Note:
Creating an Expression Dataset in the Expression Dataset Manager
- How many of the IDs were imported out of the total IDs in the microarray dataset? How many exceptions were there? Look in the EX.txt file and look at the error codes for the records that were not imported into the Expression Dataset. Do these represent IDs that were present in the UniProt XML, but were somehow not imported? or were they not present in the UniProt XML?
Note:
Coloring a MAPP with expression data
Note:
Running MAPPFinder
Note:
Compare Gene Database to Outside Resource
Note: This section applies to the Group Final Project and does not need to be completed for the Week 9 assignment. — Kdahlquist (talk) 15:46, 2 November 2015 (PST)
The OrderedLocusNames IDs in the exported Gene Database are derived from the UniProt XML. It is a good idea to check your list of OrderedLocusNames IDs to see how complete it is using the original source of the data (the sequencing organization, the MOD, etc.) Because UniProt is a protein database, it does not reference any non-protein genome features such as genes that code for functional RNAs, centromeres, telomeres, etc.
Note: