Blitvak Week 12
From LMU BioDB 2015
Contents
Important Information Regarding J2315
Sourced from the UniProt Taxonomy entry for J2315
- Names: Burkholderia cenocepacia (strain ATCC BAA-245 / DSM 16553 / LMG 16656 / NCTC 13227 / J2315 / CF5610), Burkholderia cepacia strain J2315
- TAXON ID: 216591
Initial Export/Import Cycle
Initial Preparations
- Utilized the Week 9 Assignment as a reference
In preparation for this assignment, it was ensured that these programs were installed on a Windows workstation:
- 7-zip for the unpacking of compressed files
- PostgreSQL
- GenMAPP Builder
- Java JDK 1.8 64-bit (download jdk-8u65-windows-x64.exe)
- GenMAPP 2 (download GenMAPPv2Setup.exe)
- XMLPipeDB match utility
- A program that is able to read .mdb files (such as Microsoft Access)
Downloading the Required Files
Retrieving the UniProt XML file, Performed on 11/19
- The UniProt Complete Proteomes page was entered
- The Superkingdom Bacteria was selected as a Filter By option
- "burkholderia cenocepacia J2315" was added to the search bar and search was clicked upon. One result was given that corresponded to J2315.
- The result was clicked upon and, on the result page, UniProtKB was clicked upon in the "Map to" section (on left of the page)
- On the UniProtKB results page, Download was clicked; in the box that appeared, download all was selected, the format was set to XML, and the file was set to be compressed.
Retrieving the GOA file, Performed on 11/19
- The UniProt-GOA ftp site was entered
- The link to the "proteomes" directory was clicked in the main directory
- In "proteomes", the GOA corresponding to the J2315 strain was not found; the GOA files corresponding to other B.cenocepacia strains, however, were found
- By looking over the UniProt Taxonomy page for J2315, it was found that the Taxon Identifier is 216591
- The UniProt-GOA Proteome Sets page was accessed on the EBI website; it was noticed that there was a Tax ID column and control-F was utilized in order to find an entry that corresponded to 216591. It was found that the file 31277.B_cepacia.goa was the correct GOA file
- 31277.B_cepacia.goa was found in the proteomes directory of the UniProt-GOA ftp site and downloaded
Retrieving the GO OBO-XML file, Performed on 11/19
- The GO OBO-XML file was downloaded from the Gene Ontology download page
- "obo-xml.gz" was selected/clicked under Legacy Downloads
Downloading/Updating GenMAPP Builder, Performed on 11/19
- The files were downloaded from the XMLPipeDB releases page on GitHub
- Download link for gmbuilder-3.0.0-build-5 (the version used in this assignment)
- All of the downloaded files, if compressed, were extracted using 7-Zip. All required files were placed in one folder
- Downloaded on 11/19, Summary
- The complete proteome for B. cenocepacia J2315 was downloaded from UniProtKB in the XML format
- The GOA file for B. cenocepacia J2315 was downloaded from the UniProt GOA ftp site
- The GO OBO-XML formatted file for B. cenocepacia J2315 was downloaded from the GO website
- The most recent version (3.0.0, build 5) of gmBuilder was downloaded from GitHub
Export Process
Creating a New Database in PostgreSQL
- Steps taken were sourced from the Running GenMAPP Builder page
- pgAdmin III was launched and a connection to the server was made. "Databases" was right clicked and select "New Database..." was chosen. The database was given a name, B.cenocepacia_J2315_20151119_gmb3build5, and OK was clicked.
- The new database was selected and the Query Tool was launched. Open File was clicked in the Query Tool and gmbuilder.sql in the gmbuilder-3.0.0-build-5 folder (within the sql folder) was selected. Upon selection of that file, a query was loaded into Query Tool and it was subsequently executed by clicking the green "Execute Query" arrow
- This query populates the created database with all of its tables. In order to ensure that the query properly worked, it was checked that 167 tables existed in the database
Importing Data
- gmbuilder.bat in the gmbuilder folder was launched
- Under file -> configure database, the host was left as localhost, the port number was left as 5432, database name was set to B.cenocepacia_J2315_20151119_gmb3build5, Username was set to postgres, Password was set to the password of the PostgreSQL database that was recently created. OK was clicked.
Data Import into B.cenocepacia_J2315_20151119_gmb3build5
- File -> Import UniProt XML was selected
- The UniProt XML file that was previously extracted was chosen, open was clicked. The import process was allowed to proceed uninterrupted.
- File -> Import GO OBO-XML was selected
- The GO OBO-XML that was previously extracted was chosen, open was clicked. The import process was allowed to proceed uninterrupted.
- File -> Import GOA was selected
- The GOA file that was downloaded previously was chosen, open was clicked, and the import process was allowed to proceed uninterrupted.
Exporting a GenMAPP Gene Database (.gdb file)
- File -> Export to GenMAPP Gene Database was selected
- BL was typed into the Owner field. The species of interest was selected for export (B. cenocepacia J2315)
- Next was clicked, the create GenMAPP database file/location was selected, and the boxes for the exporting of Molecular Function, Cellular Component, and Biological Process Gene Ontology Terms were left checked. The export process was initialized by clicking next; the windows were left open for the program to continue and finish with the export process (was estimated to take somewhere between 1-2 hrs).
Initial Database Testing Report
Further exploration of the ID systems for B. cenocepacia J2315
- ID formats were explored by conducting searches using the following terms:
Burkholderia cenocepacia J2315- The following databases were explored: UniProt Taxonomy, NCBI RefSeq, NCBI Gene, QuickGO (strain was found under the taxonomy menu), and the MOD for various burkholderia species
UniProt
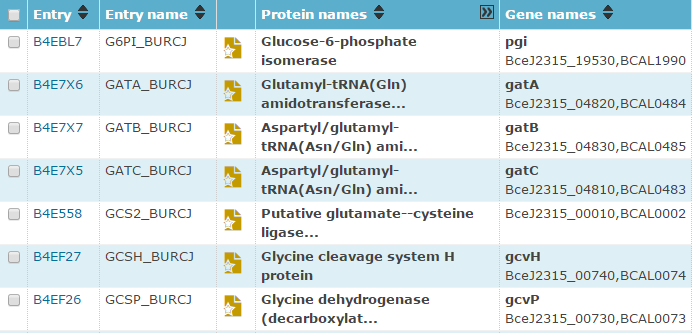
- Gene name ID: BceJ2315_#####
- ID: [B4, B3, Q4, Q8, V6]%%%% where % is either a capital letter or number

RefSeq
- Locus Tag: QU43_RS#####, also found to be in the same form as the OrderedLocusNames within the MOD
- Protein ID Format: WP_#########.1
GeneID (EntrezGene from NCBI)
- GeneID: WP_#########.1 (same as RefSeq)
GO
- GO IDs: GO:#######
OrderedLocusNames
- BCAL####[A], BCAM####[A], BCAS####[A], and pBCA###[A]: these are the most frequently encountered formats, each letter set corresponds to the replicon where the gene is located; it was also found that some IDs had an A at the end
- Uncommon ID formats included: <letterSet>r<numberSet> (these correspond to tRNA genes)
- It was also noticed that a small amount of genes included letters besides A as the final character in the ordered locus name.
Match/PGSQL Expressions for Q/A work
- Match:
java -jar xmlpipedb-match-1.1.1.jar "p?BCA[A-Z]?[0-9][0-9][0-9][A-Z]?[0-9]?[A-Z, a-z]?" < filename.xml- Notes: Originally, "p?BCA[A-Z]?[0-9][0-9][0-9][A-Z]?[0-9]?[A-Z]?" was used, but it was realized that some OrderedLocusNames contained lowercase letters at the end (form that took into account lowercases yielded a higher count)
- SQL:
select count(*) from genenametype where type = 'ordered locus' and value ~ 'p?BCA[A-Z]?[0-9][0-9][0-9][A-Z]?[0-9]?[A-Z, a-z]?';(needs further testing)- Notes: Form was modeled after what was done for xmlpipedb match, however, no entries in that OrderedLocusName ID form were actually present in the tables of the exported J2315 database; will be further tested once a modified version of GenMAPP builder is utilized to export another database.
| Weekly Group Assignments | Shared Group Journals | Project Links | Team Members |
|---|---|---|---|
|
|
|
|
|
Brandon Litvak
BIOL 367, Fall 2015
| Weekly Assignments | Individual Journal Pages | Shared Journal Pages |
|---|---|---|
|
|
|
|