Dbashour Week 14
Contents
Electronic Notebook
Week 8 Corrections
Part 1: Statistical Analysis Part 1
The purpose of the witin-stain ANOVA test is to determine if any genes had a gene expression change that was significantly different than zero at any timepoint.
- I created a new worksheet, named it "dGLN3_ANOVA".
- I copied the first three columns containing the "MasterIndex", "ID", and "Standard Name" from the "Master_Sheet" worksheet for my strain and pasted it into dGLN3_ANOVA. I copied the columns containing the data for dGLN3 and pasted it into dGLN3_ANOVA.
- At the top of the first column to the right of your data, I created five column headers of the form dGLN3_AvgLogFC_(TIME) where (TIME) is 15, 30, etc.
- In the cell below the dGLN3_AvgLogFC_t15 header, I typed
=AVERAGE( - Then I highlighted all the data in row 2 associated with dGLN3 and t15 and pressed the closing paren key (shift 0),and pressed the "enter" key.
- This cell now contains the average of the log fold change data from the first gene at t=15 minutes.
- I Clicked on this cell and positioned my cursor at the bottom right corner. You should see your cursor change to a thin black plus sign (not a chubby white one). When it does, double click, and the formula will magically be copied to the entire column of 6188 other genes.
- Repeat steps (4) through (8) with the t30, t60, t90, and the t120 data.
- for t30, I used the formula
- Now in the first empty column to the right of the dGLN3_AvgLogFC_t120 calculation, create the column header dGLN3_ss_HO.
- In the first cell below this header, type
=SUMSQ( - Highlight all the LogFC data in row 2 for your dGLN3 (but not the AvgLogFC), press the closing paren key (shift 0),and press the "enter" key.
- In the next empty column to the right of dGLN3_ss_HO, create the column headers dGLN3_ss_(TIME) as in (3).
- Make a note of how many data points you have at each time point for your strain. For most of the strains, it will be 4, but for dHAP4 t90 or t120, it will be "3", and for the wild type it will be "4" or "5". Count carefully. Also, make a note of the total number of data points. Again, for most strains, this will be 20, but for example, dHAP4, this number will be 18, and for wt it should be 23 (double-check).
- In the first cell below the header dGLN3_ss_t15, type
=SUMSQ(<range of cells for logFC_t15>)-COUNTA(<range of cells for logFC_t15>)*<AvgLogFC_t15>^2and hit enter.- The
COUNTAfunction counts the number of cells in the specified range that have data in them (i.e., does not count cells with missing values). - The phrase <range of cells for logFC_t15> should be replaced by the data range associated with t15.
- The phrase <AvgLogFC_t15> should be replaced by the cell number in which you computed the AvgLogFC for t15, and the "^2" squares that value.
- Upon completion of this single computation, use the Step (7) trick to copy the formula throughout the column.
- The
- Repeat this computation for the t30 through t120 data points. Again, be sure to get the data for each time point, type the right number of data points, and get the average from the appropriate cell for each time point, and copy the formula to the whole column for each computation.
- In the first column to the right of (STRAIN)_ss_t120, create the column header dGLN3_SS_full.
- In the first row below this header, type
=sum(<range of cells containing "ss" for each timepoint>)and hit enter. - In the next two columns to the right, create the headers dGLN3_Fstat and dGLN3_p-value.
- Recall the number of data points from (13): call that total n.
- In the first cell of the dGLN3_Fstat column, type
=((n-5)/5)*(<(dGLN3_ss_HO>-<dGLN3_SS_full>)/<dGLN3_SS_full>and hit enter.- Don't actually type the n but instead use the number from (13). Also note that "5" is the number of timepoints and the dSWI4 strain has 4 timepoints (it is missing t15).
- Replace the phrase dGLN3_ss_HO with the cell designation.
- Replace the phrase <dGLN3_SS_full> with the cell designation.
- Copy to the whole column.
- In the first cell below the dGLN3_p-value header, type
=FDIST(<dGLN3_Fstat>,5,n-5)replacing the phrase <dGLN3_Fstat> with the cell designation and the "n" as in (13) with the number of data points total. (Again, note that the number of timepoints is actually "4" for the dSWI4 strain). Copy to the whole column. - Before we move on to the next step, we will perform a quick sanity check to see if we did all of these computations correctly.
- Click on cell A1 and click on the Data tab. Select the Filter icon (looks like a funnel). Little drop-down arrows should appear at the top of each column. This will enable us to filter the data according to criteria we set.
- Click on the drop-down arrow on your dGLN3_p-value column. Select "Number Filters". In the window that appears, set a criterion that will filter your data so that the p value has to be less than 0.05.
- Excel will now only display the rows that correspond to data meeting that filtering criterion. A number will appear in the lower left hand corner of the window giving you the number of rows that meet that criterion. We will check our results with each other to make sure that the computations were performed correctly.
Calculate the Bonferroni and p value Correction
- Now we will perform adjustments to the p value to correct for the multiple testing problem. Label the next two columns to the right with the same label, (STRAIN)_Bonferroni_p-value.
- Type the equation
=<dGLN3_p-value>*6189, Upon completion of this single computation, use the Step (10) trick to copy the formula throughout the column. - Replace any corrected p value that is greater than 1 by the number 1 by typing the following formula into the first cell below the second dGLN3_Bonferroni_p-value header:
=IFdGLN3_Bonferroni_p-value>1,1,dGLN3_Bonferroni_p-value), where "dGLN3_Bonferroni_p-value" refers to the cell in which the first Bonferroni p value computation was made. Use the Step (10) trick to copy the formula throughout the column.
Calculate the Benjamini & Hochberg p value Correction
- Insert a new worksheet named "dGLN3_ANOVA_B-H".
- Copy and paste the "MasterIndex", "ID", and "Standard Name" columns from your previous worksheet into the first two columns of the new worksheet.
- For the following, use Paste special > Paste values. Copy your unadjusted p values from your ANOVA worksheet and paste it into Column D.
- Select all of columns A, B, C, and D. Sort by ascending values on Column D. Click the sort button from A to Z on the toolbar, in the window that appears, sort by column D, smallest to largest.
- Type the header "Rank" in cell E1. We will create a series of numbers in ascending order from 1 to 6189 in this column. This is the p value rank, smallest to largest. Type "1" into cell E2 and "2" into cell E3. Select both cells E2 and E3. Double-click on the plus sign on the lower right-hand corner of your selection to fill the column with a series of numbers from 1 to 6189.
- Now you can calculate the Benjamini and Hochberg p value correction. Type dGLN3_B-H_p-value in cell F1. Type the following formula in cell F2:
=(D2*6189)/E2and press enter. Copy that equation to the entire column. - Type "dGLN3_B-H_p-value" into cell G1.
- Type the following formula into cell G2:
=IF(F2>1,1,F2)and press enter. Copy that equation to the entire column. - Select columns A through G. Now sort them by your MasterIndex in Column A in ascending order.
- Copy column G and use Paste special > Paste values to paste it into the next column on the right of your ANOVA sheet.
- Zip and upload the .xlsx file that you have just created to the wiki.
Sanity Check: Number of genes significantly changed
Before we move on to further analysis of the data, we want to perform a more extensive sanity check to make sure that we performed our data analysis correctly. We are going to find out the number of genes that are significantly changed at various p value cut-offs.
- Go to your dGLN3_ANOVA worksheet.
- Select row 1 (the row with your column headers) and select the menu item Data > Filter > Autofilter (The funnel icon on the Data tab). Little drop-down arrows should appear at the top of each column. This will enable us to filter the data according to criteria we set.
- Click on the drop-down arrow for the unadjusted p value. Set a criterion that will filter your data so that the p value has to be less than 0.05.
- How many genes have p < 0.05? and what is the percentage (out of 6189)?
- How many genes have p < 0.01? and what is the percentage (out of 6189)?
- How many genes have p < 0.001? and what is the percentage (out of 6189)?
- How many genes have p < 0.0001? and what is the percentage (out of 6189)?
- When we use a p value cut-off of p < 0.05, what we are saying is that you would have seen a gene expression change that deviates this far from zero by chance less than 5% of the time.
- We have just performed 6189 hypothesis tests. Another way to state what we are seeing with p < 0.05 is that we would expect to see this a gene expression change for at least one of the timepoints by chance in about 5% of our tests, or 309 times. Since we have more than 309 genes that pass this cut off, we know that some genes are significantly changed. However, we don't know which ones. To apply a more stringent criterion to our p values, we performed the Bonferroni and Benjamini and Hochberg corrections to these unadjusted p values. The Bonferroni correction is very stringent. The Benjamini-Hochberg correction is less stringent. To see this relationship, filter your data to determine the following:
- How many genes are p < 0.05 for the Bonferroni-corrected p value? and what is the percentage (out of 6189)?
- How many genes are p < 0.05 for the Benjamini and Hochberg-corrected p value? and what is the percentage (out of 6189)?
- In summary, the p value cut-off should not be thought of as some magical number at which data becomes "significant". Instead, it is a moveable confidence level. If we want to be very confident of our data, use a small p value cut-off. If we are OK with being less confident about a gene expression change and want to include more genes in our analysis, we can use a larger p value cut-off.
- We will compare the numbers we get between the wild type strain and the other strains studied, organized as a table. Use this sample PowerPoint slide to see how your table should be formatted. Upload your slide to the wiki.
- Note that since the wild type data is being analyzed by one of the groups in the class, it will be sufficient for this week to supply just the data for your strain. We will do the comparison with wild type at a later date.
- Comparing results with known data: the expression of the gene NSR1 (ID: YGR159C)is known to be induced by cold shock. Find NSR1 in your dataset. What is its unadjusted, Bonferroni-corrected, and B-H-corrected p values? What is its average Log fold change at each of the timepoints in the experiment? Note that the average Log fold change is what we called "dGLN3_AvgLogFC_(TIME)" in step 3 of the ANOVA analysis. Does NSR1 change expression due to cold shock in this experiment?
- For fun, find "your favorite gene" (from your web page) in the dataset. What is its unadjusted, Bonferroni-corrected, and B-H-corrected p values? What is its average Log fold change at each of the timepoints in the experiment? Does your favorite gene change expression due to cold shock in this experiment?
Week 10 Corrections
Week 10 Continued
Using YEASTRACT to Infer which Transcription Factors Regulate a Cluster of Genes
In the previous analysis using STEM, we found a number of gene expression profiles (aka clusters) which grouped genes based on similarity of gene expression changes over time. The implication is that these genes share the same expression pattern because they are regulated by the same (or the same set) of transcription factors. We will explore this using the YEASTRACT database.
- I opened the gene list in Excel for profile 45 of my stem analysis. I chose this cluster because it had a cold shock/recovery up/down or down/up pattern and it was one of the largest clusters.
- I then copied the list of gene IDs onto my clipboard.
- I launched a web browser and went to the YEASTRACT database.
- On the left panel of the window, I clicked on the link to Rank by TF.
- I pasted my list of genes from my chosen cluster into the box labeled ORFs/Genes.
- Check the box for Check for all TFs.
- Accept the defaults for the Regulations Filter (Documented, DNA binding plus expression evidence)
- Do not apply a filter for "Filter Documented Regulations by environmental condition".
- Rank genes by TF using: The % of genes in the list and in YEASTRACT regulated by each TF.
- Click the Search button.
- Answer the following questions:
- In the results window that appears, the p values colored green are considered "significant", the ones colored yellow are considered "borderline significant" and the ones colored pink are considered "not significant". How many transcription factors are green or "significant"?
- There are 30 green or significant transcription factors.
- I copied the table of results from the web page and pasted it into a new Excel workbook to preserve the results.
- I upload the Excel file to Box and link to it below in the deliverables section of this wiki, naming it "Yeastract_Results_DB_Gene_hAPI.
- My transcription factor is on the list. It's % in user set is 0.3085%, its % in yeastract is 0.1044%, and its p value is 1E-13.
- I copied the table of results from the web page and pasted it into a new Excel workbook to preserve the results.
- For the mathematical model and GRNsight, we need to define a gene regulatory network of transcription factors that regulate other transcription factors. We can use YEASTRACT to assist us with creating the network. We want to generate a network with approximately 15-30 transcription factors in it.
- I chose all 30 of the significant transcription factors on my list, adding HAP4 since it was not already on the list. I chose these transcription factors among the rest because they are all significant so this way I can analyze all the significant TFs keeping in mind their % in user set, % in yeastract, and p value. All 30 TFs are listed below.
- Sfp1p
- Msn2p
- Yhp1p
- Yox1p
- Ace2p
- Gln3p
- Yap1p
- Pdr3p
- Ume6p
- Pdr1p
- Stb5p
- Swi5p
- YLR278C
- Mig2p
- Asg1p
- Tup1p
- Gcr2p
- Msn4p
- Rim101p
- Gcn4p
- Sut1p
- Mcm1p
- Met4p
- Rlm1p
- Ino4p
- Ndt80p
- Zap1p
- Abf1p
- Cyc8p
- Gat3p
- I then went to the link Generate Regulation Matrix on the yeastract database and copied and pasted the list of transcription factors above into both the "Transcription factors" field and the "Target ORF/Genes" field.
- We are going to use the "Regulations Filter" options of "Documented", "Only DNA binding evidence"
- Click the "Generate" button.
- In the results window that appears, click on the link to the "Regulation matrix (Semicolon Separated Values (CSV) file)" that appears and save it to your Desktop. Rename this file with a meaningful name so that you can distinguish it from the other files you will generate.
- I chose all 30 of the significant transcription factors on my list, adding HAP4 since it was not already on the list. I chose these transcription factors among the rest because they are all significant so this way I can analyze all the significant TFs keeping in mind their % in user set, % in yeastract, and p value. All 30 TFs are listed below.
Visualizing Your Gene Regulatory Networks with GRNsight
We will analyze the regulatory matrix files you generated above in Microsoft Excel and visualize them using GRNsight to determine which one will be appropriate to pursue further in the modeling.
- First we need to properly format the output files from YEASTRACT. You will repeat these steps for each of the three files you generated above.
- Open the file in Excel. It will not open properly in Excel because a semicolon was used as the column delimiter instead of a comma. To fix this, Select the entire Column A. Then go to the "Data" tab and select "Text to columns". In the Wizard that appears, select "Delimited" and click "Next". In the next window, select "Semicolon", and click "Next". In the next window, leave the data format at "General", and click "Finish". This should now look like a table with the names of the transcription factors across the top and down the first column and all of the zeros and ones distributed throughout the rows and columns. This is called an "adjacency matrix." If there is a "1" in the cell, that means there is a connection between the trancription factor in that row with that column.
- Save this file in Microsoft Excel workbook format (.xlsx).
- I checked to see that all of the transcription factors in the matrix are connected to at least one of the other transcription factors by making sure that there is at least one "1" in a row or column for that transcription factor. If a factor is not connected to any other factor, it was deleted, making sure that I still had somewhere between 15 and 30 transcription factors in my network after this pruning.
- Only delete the transcription factor if there are all zeros in its column AND all zeros in its row. You may find visualizing the matrix in GRNsight (below) can help you find these easily.
- For this adjacency matrix to be usable in GRNmap (the modeling software) and GRNsight (the visualization software), we need to transpose the matrix. Insert a new worksheet into your Excel file and name it "network". Go back to the previous sheet and select the entire matrix and copy it. Go to you new worksheet and click on the A1 cell in the upper left. Select "Paste special" from the "Home" tab. In the window that appears, check the box for "Transpose". This will paste your data with the columns transposed to rows and vice versa. This is necessary because we want the transcription factors that are the "regulatORS" across the top and the "regulatEES" along the side.
- The labels for the genes in the columns and rows need to match. Thus, delete the "p" from each of the gene names in the columns. Adjust the case of the labels to make them all upper case.
- In cell A1, copy and paste the text "rows genes affected/cols genes controlling".
- Finally, for ease of working with the adjacency matrix in Excel, we want to alphabatize the gene labels both across the top and side.
- Select the area of the entire adjacency matrix.
- Click the Data tab and click the custom sort button.
- Sort Column A alphabetically, being sure to exclude the header row.
- Now sort row 1 from left to right, excluding cell A1. In the Custom Sort window, click on the options button and select sort left to right, excluding column 1.
- Name the worksheet containing your organized adjacency matrix "network" and Save.
- Now we will visualize what these gene regulatory networks look like with the GRNsight software.
- Go to the GRNsight home page.
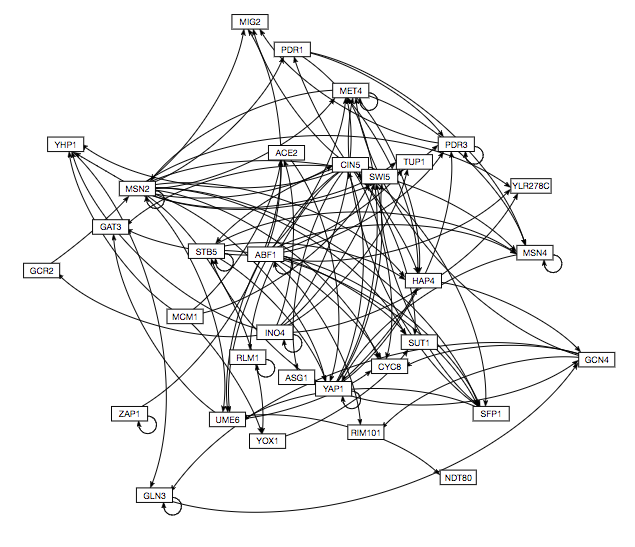
- Select the menu item File > Open and select the regulation matrix .xlsx file that has the "network" worksheet in it that you formatted above. If the file has been formatted properly, GRNsight should automatically create a graph of your network. Move the nodes (genes) around until you get a layout that you like and take a screenshot of the results. Paste it into your PowerPoint presentation.
Summary of what you need to turn in for the individual Week 10 assignment
- Your individual journal page should have an electronic lab notebook recording your work. This includes the detailed methods specific to your analysis, your result files, the answers to any questions posed in the protocol above, a scientific conclusion, and the acknowledgments and references sections. Don't forget your paragraph which is a biological interpretation of your stem results.
- Upload your updated Excel spreadsheet to the wiki that has today's manipulations in it. Use the same filename as before so that the download link that you already (previous versions will still be available in the history).
- Append the screenshots of the stem results to the PowerPoint presentation that contains the p value table that you created for the Week 8 assignments. Each slide in the presentation should have a meaningful title that describes the main message of the slide.
- Zip together all of the tab-delimited text files that you created for and from stem and upload them to the wiki.
- the file that was saved from your original spreadsheet that you used to run stem
- each of the genelist and GOlist files for each of your significant profiles.
- Write a paragraph-length conclusion for this week's exercise.
Deliverables
DGLN3 ANOVA/Stem
DGLN3 ppt Dina
DGLN3 Gene List and GO list
Yeastract TF List
GRNmap dGLN3 input
GRNmap dGLN3 output
{kind=link}