Difference between revisions of "Ckaplan Week 10"
(adding reference and acknowledgements) |
(adding sources) |
||
| Line 90: | Line 90: | ||
*Select 6 Gene Ontology terms and give definitions: | *Select 6 Gene Ontology terms and give definitions: | ||
| − | GO:0000027 "The aggregation, arrangement and bonding together of constituent RNAs and proteins to form the large ribosomal subunit." Source: GOC:jl, PMID:30467428 | + | GO:0000027 "The aggregation, arrangement and bonding together of constituent RNAs and proteins to form the large ribosomal subunit." Source: GOC:jl, PMID:30467428 https://amigo.geneontology.org/amigo/term/GO:0000027 |
| − | GO:0034475 "Any process involved in forming the mature 3' end of a U4 snRNA molecule." Source: GOC:mah | + | GO:0034475 "Any process involved in forming the mature 3' end of a U4 snRNA molecule." Source: GOC:mah https://amigo.geneontology.org/amigo/medial_search?q=GO%3A0034475 |
| − | GO:0003676 "Binding to a nucleic acid." Source: GOC:jl | + | GO:0003676 "Binding to a nucleic acid." Source: GOC:jl https://amigo.geneontology.org/amigo/medial_search?q=GO%3A0003676 |
| − | GO:0019843 "Binding to a ribosomal RNA." Source: GOC:jl | + | GO:0019843 "Binding to a ribosomal RNA." Source: GOC:jl https://amigo.geneontology.org/amigo/medial_search?q=GO%3A0019843 |
| − | GO:0005654 "That part of the nuclear content other than the chromosomes or the nucleolus." Source: GOC:ma, ISBN:0124325653 | + | GO:0005654 "That part of the nuclear content other than the chromosomes or the nucleolus." Source: GOC:ma, ISBN:0124325653 https://amigo.geneontology.org/amigo/medial_search?q=GO%3A0005654 |
| − | GO:0000055 "The directed movement of a ribosomal large subunit from the nucleus into the cytoplasm." Source: GOC:mah | + | GO:0000055 "The directed movement of a ribosomal large subunit from the nucleus into the cytoplasm." Source: GOC:mah https://amigo.geneontology.org/amigo/medial_search?q=GO%3A0000055 |
===Acknowledgments=== | ===Acknowledgments=== | ||
Revision as of 19:56, 3 April 2024
Contents
Purpose:
This assignment helps us learn microarray data analysis and gene analysis techniques. It also provides practice in determining p-values and organizing data effectively.
Procedure:
To prepare my microarray data file for loading into STEM, I first inserted a new worksheet into my Excel workbook and named it "dgln3_stem". Then, I copied all the data from my "dgln3_ANOVA" worksheet and pasted special > paste values into my new worksheet.
Next, I ensured that the leftmost column had the column header "Master_Index" and renamed it to "SPOT". Column B was named "ID", which I renamed to "Gene Symbol". I deleted the column named "Standard_Name".
I filtered the data based on the B-H corrected p-value to be > 0.05, ensuring that only genes with a significant change in expression remained. After filtering, I deleted the rows with non-significant changes by selecting all rows except the header row and right-clicking to choose "Delete Row" from the context menu. Then, I undid the filter.
Following that, I deleted all data columns except for the Average Log Fold Change columns for each timepoint, such as "dgln3_AvgLogFC_t15", etc. I renamed these data columns with just the time and units, like "15m", "30m", etc.
To address any remaining #DIV/0! errors, I opened the Find/Replace dialog, searched for #DIV/0!, and replaced it with nothing. This ensured that no errors were left in the data.
After saving my work, I used Save As to save the spreadsheet as Text (Tab-delimited) (*.txt) and clicked OK to the warnings before closing the file.
Moving on to running STEM, I downloaded and extracted the STEM software, then launched the stem.jar file inside the stem folder.
In section 1 of the main STEM interface window (Expression Data Info), I browsed and selected my file, chose "No normalization/add 0", and checked the box for Spot IDs included in the data file.
For section 2 (Gene Info), I left the default selections for Gene Annotation Source, Cross Reference Source, and Gene Location Source as "User provided". I then browsed and selected the "gene_association.sgd.gz" file from the stem folder for the Gene Annotation File.
In section 3 (Options), I made sure the Clustering Method was set to "STEM Clustering Method" and left the defaults for Maximum Number of Model Profiles and Maximum Unit Change in Model Profiles between Time Points.
Finally, in section 4 (Execute), I clicked the Execute button to run STEM.
Upon completion, I viewed and saved the STEM results. I took screenshots of the "All STEM Profiles" window and individual profile windows, saving them in a PowerPoint presentation.
For each significant profile, I saved the gene list and GO terms list.
Now, onto analyzing and interpreting the STEM results, I selected a profile with a clear cold shock/recovery pattern for further investigation. I chose profile 45 because it seemed to reflect a significant response to the cold shock conditions and had the largest amount of genes.
The number of genes belonging to this profile, as well as the expected number, and the p-value for the enrichment of genes in this profile, were noted.
I then opened the GO list file for this profile in Excel, filtered the terms based on p-values and corrected p-values < 0.05, and noted the number of associated GO terms meeting these criteria.
Next, I selected six significant GO terms from the filtered list, ensuring they were meaningful in the context of the gene expression profile.
I also checked the YEASTRACT database to infer which transcription factors regulate the genes in my selected profile. After pasting my list of genes into the YEASTRACT database, I identified the significant transcription factors and recorded their details, including whether CIN5 or GLN3 were on the list.
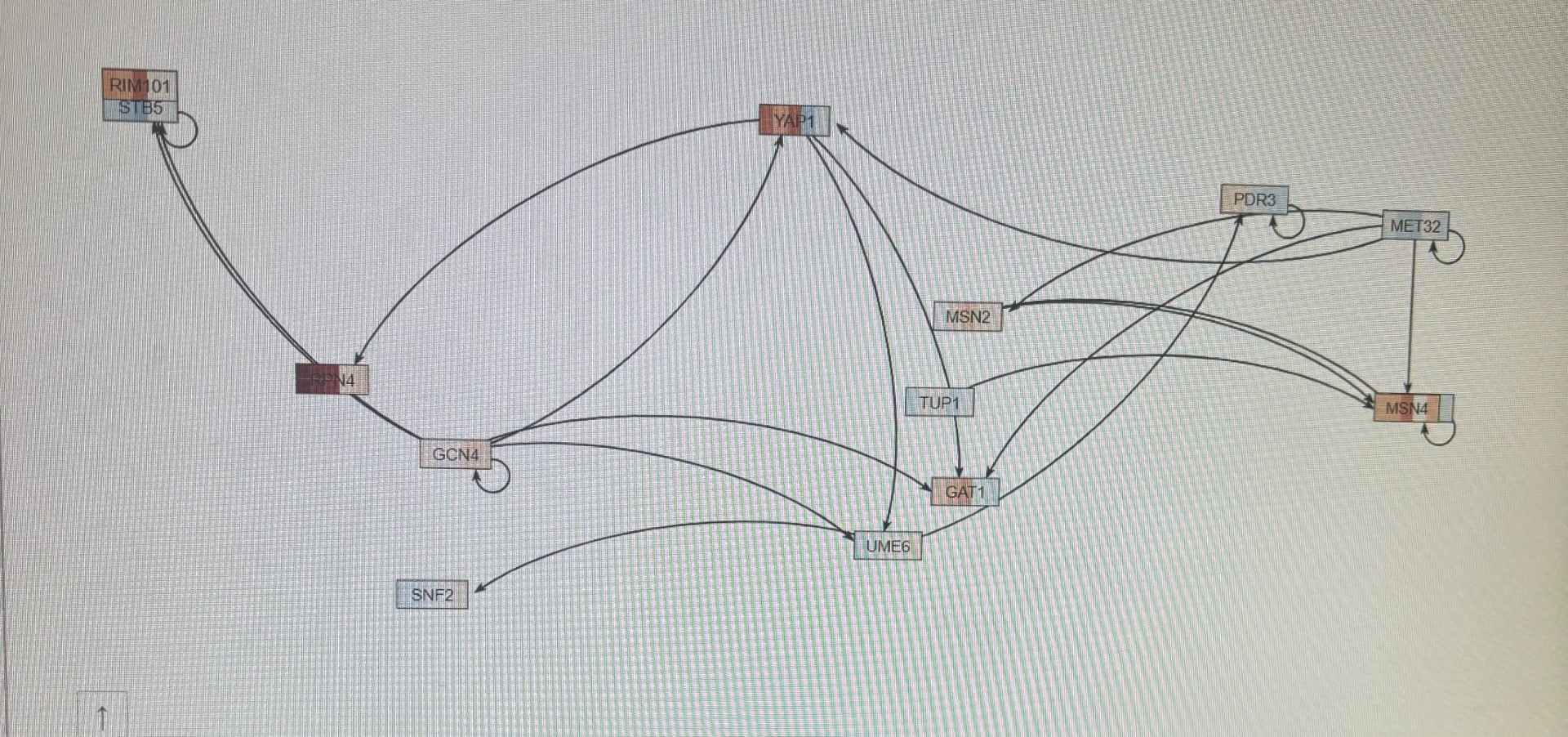
Lastly, I used GRNsight to create and visualize a gene regulatory network with approximately 15-20 connected transcription factors, including GLN3 and CIN5 if necessary. I recorded the number of genes and edges in the network and exported the network image.
For creating the GRNmap input workbook, I exported the data from GRNsight to Excel, ensuring all necessary sheets and data were present and correctly formatted. I inserted a new worksheet named "network_weights" and copied the contents of the "network" sheet into it.
Finally, I saved and uploaded my Excel Workbook to the wiki, linking it to my individual journal page for further analysis.
Methods/Results:
Media: BIOL367_S24_microarray-data_dGLN3CKAS31211.xlsx
Media:Updated_Pvalues_ckaplan.pdf
Media:Andrew&Charlotte_Tables_Gene-GoData.zip
Media:AS&CK_BIOL367_S24_STEM_PHOTOS_dGLN3.pptx
Media:Yeastract_45_Gene_CK.xlsx
Media:GRN_(Yeastmine_-_SGD__2024-03-19;_13_genes,_21_edges)_weighted_(2)_ck_45.xlsx
{kind=link}
- How many GO terms are less than 0.05?
-Started with 160- after filtering 72. Then after filtering corrected p values I got 12.
- Why did you select this profile? In other words, why was it interesting to you?
I selected profile 45 because I thought it was interesting because out of all off our profiles, it had the most genes.
- How many genes belong to this profile?
406
- How many genes were expected to belong to this profile?
29.9
- What is the p value for the enrichment of genes in this profile?
0.00
- How many significant green genes?
I have 44 green genes
- Are Gln3p and Cin5p present? What are the percentages?
Gln3p 46.65% Cin5p 31.27%
- Genes and edges in my network:
13 genes and 14 edges
- Select 6 Gene Ontology terms and give definitions:
GO:0000027 "The aggregation, arrangement and bonding together of constituent RNAs and proteins to form the large ribosomal subunit." Source: GOC:jl, PMID:30467428 https://amigo.geneontology.org/amigo/term/GO:0000027
GO:0034475 "Any process involved in forming the mature 3' end of a U4 snRNA molecule." Source: GOC:mah https://amigo.geneontology.org/amigo/medial_search?q=GO%3A0034475
GO:0003676 "Binding to a nucleic acid." Source: GOC:jl https://amigo.geneontology.org/amigo/medial_search?q=GO%3A0003676
GO:0019843 "Binding to a ribosomal RNA." Source: GOC:jl https://amigo.geneontology.org/amigo/medial_search?q=GO%3A0019843
GO:0005654 "That part of the nuclear content other than the chromosomes or the nucleolus." Source: GOC:ma, ISBN:0124325653 https://amigo.geneontology.org/amigo/medial_search?q=GO%3A0005654
GO:0000055 "The directed movement of a ribosomal large subunit from the nucleus into the cytoplasm." Source: GOC:mah https://amigo.geneontology.org/amigo/medial_search?q=GO%3A0000055
Acknowledgments
I worked with Andrew multiple times in and out of class throughout the week. He helped me if I got lost or behind in class. We communicated over message for any questions. Dr. Dahlquist assisted us in class.
References
Dahlquist, K. Master_sheet_dGLN3.
LMU BioDB 2024. (2024). Week 9. Retrieved Mar 20, 2024, from https://xmlpipedb.cs.lmu.edu/biodb/Spring2024/index.php/Week_9
LMU BioDB 2024. (2024). Week 9. Retrieved Mar 31, 2024, from https://xmlpipedb.cs.lmu.edu/biodb/spring2024/index.php/Week_10
Assignment Pages
- Week 1
- Week 2
- Week 3
- Week 4
- Week 5
- Week 6
- Week 8
- Week 9
- Week 10
- Week 11
- Week 12
- Week 13
- Week 14
- Week 15
Individual Journal Entry Pages
- ckaplan Week 1
- ckaplan Week 2
- SIR2 Week 3
- AgeAnnoMO Week 4
- ckaplan Week 5
- ckaplan Week 6
- ckaplan Week 8
- ckaplan Week 9
- ckaplan Week 10
- ckaplan Week 11
- ckaplan Week 12
- ckaplan Week 13
- ckaplan Week 14
- ckaplan Week 15